您正在访问旧版存档页面。This is the old version archive of our site.

古籍文献中纪时实体信息的提取方法及实现研究
作者: 陈逸云 / 搜韵网
基础设施

陈逸云 / 搜韵网
摘 要:从古籍文本中自动提取时间类实体信息,对知识图谱的建设及应用有重要价值。古代纪时方式,张衍田在《中国古代纪时考》一书中已言之甚详。然而,要转化成技术,仍会有很多困难。一是日期样式灵活多变,且同位语很多;二是日期常因上下文而从简,以至于若非结合上下文所述及的人物或历史背景,没法推断确切时间;三是对于区分度不高的纪时词汇,有消歧的困难;四是标签化结果需要得到合适的解释和规范化,才能转化成计算机的知识,以便在应用研发中发挥更好的作用。由此可见,提取纪时实体信息,仍需配合诸如人物、地理和朔闰表等其它知识库,才能达到理想的精度及知识深度。文章以字典树、决策树和朴素贝叶斯为技术基础,以作者所研发的网站为应用案例,阐述在研发过程中碰到的各种问题及其解决方法,提出用于提高精度的双层分析模型。第一层模型注重局部优化,在有限的上下文信息中,优化和解释标签化结果;第二层模型则从更大的广度上,对局部结果进行消歧、完善和评价。评价的结果,又可形成反馈,重新进入双层模型再次优化成果,或提高原有的置信度,或抛弃经确认后置信度太低的结果,从而达到提升整体精度的效果。应用场景上,一是将研发过程中的技术,转化成可供学者在线使用的小工具;二是对文史类典籍按纪时信息重编,协助文史界学者的研究工作。
关键词: 古代纪时 标签化 知识图谱
一、概述
时间类信息,广泛地存在于古典书籍中。对时间类信息的提取,是构建数字人文领域知识图谱的重要一环。以帝系、年号、干支等要素构建的中国古代纪年、纪日方式,与规范的公元纪年截然不同。灵活多变以及上下文相关性,大大增加了时间类信息的检索和提取难度。关于古代纪时方式,张衍田在《中国古代纪时考》[1]一书中已言之甚详,在此不再赘述。本文着重讨论技术转化过程中遇到的各种难题,以及其解决方案,最后简述技术成果的若干应用。
二、提取纪时信息的四大难题
(一)样式多变,同位语繁多
中国古代纪年要素主要包括:朝代、君主、年号、执政或改元后第几年、干支。组合方式很灵活,基本上来说,只要能够确定年份的,都是有可能出现的。在有年号之前,史书一般是通过君主的统治时间来纪年,如“汉高帝七年”。由于刘邦是汉朝第一位皇帝,又有直接省作“汉七年”的。干支与年份,也可以同时出现,如“乾隆十六年辛未二月”。君主本身,会有多种称呼方式,如“李隆基”,有“唐明皇”“唐玄宗”等不同称谓。同样,月份和日期,也有很多同位语。如“七月”,可书作“上秋”“孟秋”“兰秋”“新秋”等多种方式。初一,可作“朔日”“月旦”“吉旦”,“初二”可作“既朔”。节日“端午”可作“端阳”“重午”“菖蒲节”“浴兰令节”等。甚至既可作年份,又可作日期的干支,也有同位语,如“甲子”又作“阏逢困敦”。凡此种种,皆需纳入考虑。另外,纪时还有一些修饰性字词,如“岁在”“维”“在位”等。此类信息,虽然并不会影响最终的纪时结果,但也需一并纳入考虑,以提升纪时信息的识别度。
因此,建立同位语表以及纪时表述模式,是识别纪时文本片段起止位置,以及析取其中年、月、日、时间各构成要素的重要基础。如此,才能识别诸如“维熙宁九年岁次丙辰十二月乙未朔二十四日戊午”“清乾隆四十七年巧月吉旦”之类的复杂纪时文本。
(二)因上下文或创作背景而从略
由于行文的连续性,史书记载,下文往往因前文而从简。例如《史记·高祖本纪》,前言“汉元年十月,沛公兵遂先诸侯至霸上”,后面行文则从略直接言“十一月”“十二月”“二年”“三年”等。计算机若要判断“二年”“三年”究竟是哪一年,则必须根据前文来推断。个人文学作品,常直接用干支在题目点出创作时间。如北宋韩琦《甲辰冬雨》诗、沈辽《甲辰年五月十五日夜澧阳观月》诗,计算机需根据作者生卒时间,才能准确计算出甲辰究竟是哪一年。一些节日因为日期的特殊性,也会有从简的情况。例如,东晋陶潜《九日闲居并序》,“九日”特指九月初九。唐万楚《五日观妓》,“五日”指端午。类似的,还有“晦日”“三日”。纪时信息的从简,给消歧带来了很大挑战。例如,同是标题中含“三日”,也可能是指“三天”。
(三)消歧困难
纪时描述越完整,则计算机分析越容易。简单且往往一词多义的词汇,最容易产生歧义。例如,“清明”可能只是清澈明朗之意,非指清明节;三月,可能指三个月而不是阳春三月;上元,可能是指上元县而不是元宵节;年号“永和”,可能是东汉永和年,也可能是东晋永和年,甚至可能是人名。要消除歧义,仍需借助上下文和作者的时代背景。例如,借助在同一段落中述事,时间线一般是单向推移的,可排除那些引起时间线错乱的年份或月份。借助作者的生卒时间,可得到文中述及时间的上限。借助各个节日中的常见相关词汇,可提升置信度。因此,即便只是做纪时类信息的提取,也需要借助地理、人物等其他知识图谱,才能有更好的精度。
(四)计算机知识化
识别出表示纪时信息的文本片段,只是第一步。需要将这些信息规范化,变成计算机能够理解的形式,才能变成计算机智能。例如,“九月十一日”和“重阳后二日”两种表述实指同一天。“南唐升元六年”与“辽太宗会同五年”都是公元942年。计算机首先需要将历法和各个朝代的君主统治时间、年号信息程序化,才能对不同时间片段进行理解、演算,规范化成统一的数字形式。
年份的计算,可通过集合求交集的方式进行。例如,朝代、君主统治时段、年号、干支纪年,都代表着一个可能的时间段或时间点集合,通过交集运算,即可得到结果。结果可能是具体的某一年,也可能是一个时间范围。例如,文中或许只是模糊地提到“政和间”或“雍乾间”,这时提取的结果,将是一个时间段,而不是某一年。年号的合法时间范围,还需考虑地域因素,以及多位君主共用一个年号,或者某些君主不连续执政的情况。例如,一般认为崇祯年号对应的时间段是从1628年至1644年,共17年。但是,作为明朝附属的朝鲜王朝,以遗民自居,继续沿用崇祯年号将近三百年。所以在文献中,会见到“崇祯四戊午仲夏日”“崇祯二百卅四年重光作噩正夏之吉”之类的纪时方式。因此,对于此类情况,计算机需要能够以崇祯年号为起点进行推演。又如晋愍帝的“建兴”年号,被前凉张寔、张茂、张骏和张重华等多位君主使用。
三、提取纪时信息的技术路线
图1是作者所建“知识图谱网”[2]提取古汉语纪时信息所采用的技术路线。
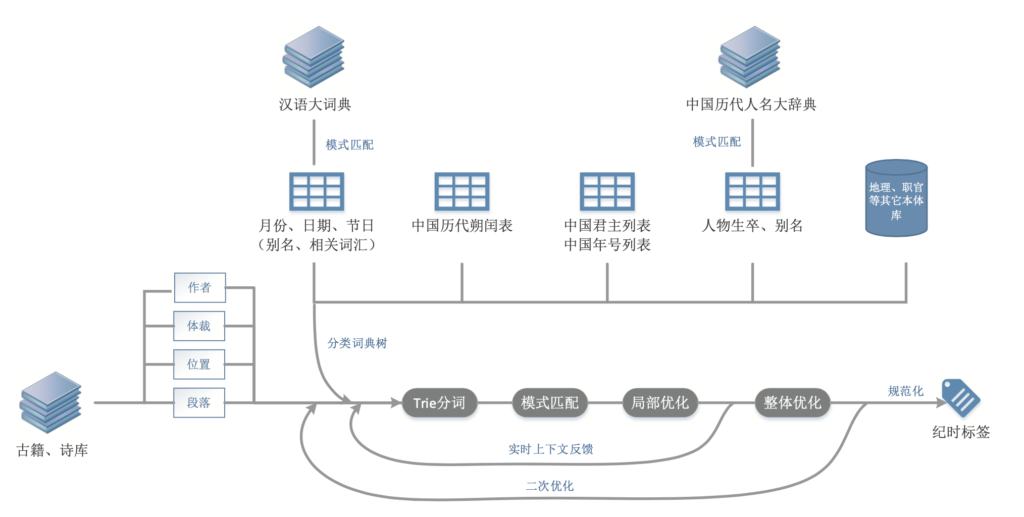
图1 提取古代纪时信息的技术路线
中国君主及年号列表,主要来自维基百科,中国历代朔闰表取自饶尚宽《春秋战国秦汉朔闰表》[3]和陈垣《二十史朔闰表》。[4]月份、日期和节日基础信息,主要提取自《汉语大词典》,[5]特别是别名和相关词汇部分。词典释义体例比较一致,这使得采用一般的模式匹配方法,便可轻松得到别名和相关词汇表。人物生卒及别名,主要提取自《中国历代人名大辞典》,[6]另参《全唐诗》《全宋诗》以及其他总集类书籍。至于诸如地理、职官等本体信息库,因不是本文的重点,在此不作阐述。以上数据构成分类词典树,为Trie分词提供基础。
来自古籍和诗库的待分析文本,除作者信息外,其文本在整个作品中所处的位置,以及作品的体裁信息,对提升准确性,也有帮助。例如,诗题、序、正文、按语和注释,前三者来自作者手笔,纪时信息不会超过作者卒年上限,这有利于消歧。而后二者,或是后人所加,时间上限具有不确定性。又如前所述,重阳、上巳和端午之类的特殊日子,可直接省作“九日”“三日”和“五日”等。这种情况一般只出现在题目,极少出现在诗句,这对消歧也有帮助。体裁则对分词的正确性有帮助。特别是诗类语言,句法非常灵活,采用时下自然语言的分词方式,往往不能奏效。如果知道文本来自律句,那么可借助律句的常用结构,来辅助决定分词方式。对于词,则可借助一些词谱中某句要求用领字的规定,来协助分词。诗词的句式,也不能处理所有的分词问题。特别是律句的末三字,有不少句子,前两字或后两字,都可以成词。要提高切分的准确率,还得借助词汇结构分析以及词频。因此,作者所采用的,实际是基于上述内容改进之后的Trie分词算法。
分词的结果,需经过后面的模式匹配,进行二次确认或增强。如前所述,纪时方式非常灵活,不适合采用穷举方式去匹配完整的纪时文本段。考虑到一个完整的纪时文本段,每一个片段是可穷举的。例如“嘉靖己未秋九月吉旦”,年号、干支、月份和日期,皆有特定取值范围。因此,本文在技术实现上,是采取先匹配各个纪时片段,再用决策树一类的方法,综合上下文推演出整个纪时文本段的边界。对于有歧义的情况,可借助朴素贝叶斯一类的算法,来协助消歧。例如诗题含关键词“五日”,且诗中提及一个或多个与端午有关的词汇,如“龙舟”或“蒲艾”之类,则可判断“五日”即指“端午”。
局部优化,是指相距比较近的前后文,互相参照进行优化。例如,古人习惯用年号纪年,但是年号有不少重名的情况。这时如前后文有提及某位人物,那么就可借助这位人物的生卒年或朝代信息来消歧、优化结果。
后文因前文而从省的情况,还出现在人名上。如《明史》:“洪武二年春,以偏将军从右副将军常遇春出塞,薄上都,走元帝,语具《遇春传》。遇春卒……”[7],前用全名“常遇春”,后省作“遇春”。本系统在分析到“常遇春”时,便会把发现人名这一上下文信息,实时反馈到Trie分词模块,这样后文分析到“遇春”时,便知道此处是指“常遇春”,与春季全无关干系。这种实时反馈,既提升了分词的准确性,又避免了误判。
在整篇分析完成之后,系统将综合分析全文的时间线,进一步消歧或删汰。这对于史书和人物传记一类的文体,非常有效。在完成全局优化并标识了置信度比较高的各类标签之后,又可重复整个过程,做二次优化。新输入的文本中,这些置信度比较高的标签有利于划定文本片段边界,减少噪音,提高分词的准确性。
综上所述,整个技术实现中,基础数据的整理,提供了Trie分词的数据基础,决策树、朴素贝叶斯和实时上下文反馈技术,增强了Trie分词的精度和纪时标签识别的准确性。标签结果的优化,则可看作是一个双层模型。第一层注重局部优化,在有限的上下文信息中,优化和解释标签化结果;第二层则从更大的广度上,对局部结果进行消歧、完善和评价。评价的结果,又可形成反馈,重新进入双层模型再次优化成果,或提高原有的置信度,或抛弃经确认后置信度太低的结果,从而达到提升整体精度的效果。
(一)模式匹配
模式匹配是提取纪时信息的核心部分之一。词典树同时定义了每个关键词的类型信息,以便在进行模式匹配时,根据每一类信息的约束条件和特征进行运算。运算目标是得到规范化的名称,以及尽可能具体地对应公元年和农历月日信息。各种类型信息和运算方法具体如表1。
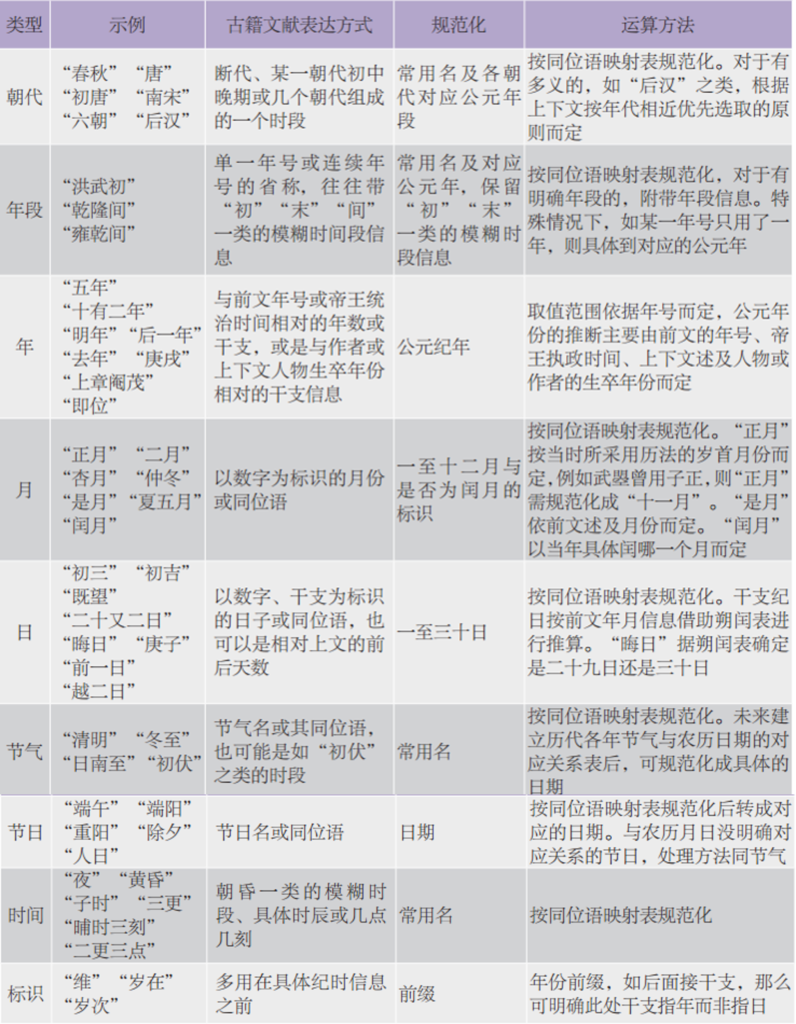
表1 时间信息运算方法举例
(二)局部优化
模式匹配时常会遇到因一词多义而难以推断确切时间的情况。由于史书中大量采用因前文而从省的相对时间记事,所以这一不准确性,又会影响到后面大量的时间推断。例如,《宋书》卷一《武帝本纪》中始言“义熙元年”,下文直至第二卷前半,皆只用相对前文的年份及月日纪时,不再有年号信息。“东晋”和“高昌”皆有“义熙”年号,如在第一卷中没正确计算出“义熙元年”的公元年,那么将有接近一卷的时间信息,没法准确推断。可见,虽然一词多义的情况大约只占10%,但这10%,有可能会影响到大半个篇幅时间记录的准确性。要提高多义年号的准确性,还得借助上下文的其它信息进行优化。有两类信息对此极有帮助,一是邻近上下文能准确推断的纪年信息;二是上下文述及的人物的生卒时间。对于前者,可取与其年代距离最接近的年号;对于后者,可取与作者生卒年有交集的年号。以《北史》卷四第一段“世宗宣武皇帝讳恪,孝文皇帝第二子也……太和七年闰四月,生帝于平城宫”[8]为例,共有六位皇帝用过“太和”年号,基于前文提及“世宗宣武皇帝”和“孝文皇帝”,可确定此处“太和”是指北魏孝文帝拓拔宏所使用的“太和”年号。
(三)整体优化
局部优化只考虑相近的上下文,遇到比较复杂的时间线,会容易受影响,特别是在文中突然追述陈年往事,或者是筹划来年的时候。例如,《清史稿》卷六“顺治十八年正月丙辰,世祖崩,帝即位,年八岁,改元康熙。……二月癸未,上释服”[9],“顺治十八年”,即1661年,改元康熙,真正生效是在1662年,如果在分析到“改元康熙”后即开始按1662年推算,则“二月癸未”开始便会出现一系列的错误。又如,《南齐书》卷二“(建元元年)冬十月丙子,立彭城刘胤为汝阴王……辛巳,诏曰:‘朕婴缀世务……宋元徽二年以来,诸从军得官者……’”[10],前“冬十月丙子”承上“建元元年”(479年),后回述“宋元徽二年”(474年),如不加审察,则会导致后文日期错讹。局部没法解决的问题,则须从整体着手。一个比较有效的解决办法是,先从全局出发,确立主体的时间线,这样即便中间偶有偏离,仍可回到主线上。每一段落开始时提及的时间,对确立主体时间线尤有帮助。
另一个局部不好解决的问题,即是干支既可用来纪年,又可用来纪日。这时可从整体进行分析,如果多见月份加干支的纪日方式,则可确定文中只出现干支之处,是用于纪日,而非纪年。
(四)准确度评价
本研究主要从以下四个方面对技术成果的准确度进行评价。
一是对于每一个纪时实体,电脑分“待确认”“低”“中”“高”四个档次进行评分。例如,当年号有多个可能时,一开始的置信度是“待确认”,如能在比较近的上下文找到一位人物的生卒时间进行确认,置信度即会据此变成“中”,如果能印证的人物多于一位,那么置信度即变成“高”。
二是借助文中朔日干支标记进行准确性校验。一些史书作者在用干支纪日时,如果恰逢朔日,会有意识地提及,以便读者据此推断后面日期。这为计算机自动校验提供了大量的样本。例如,“二年春正月戊戌朔”“八月壬申朔”,计算机可根据这些朔日,自行校对年份推断的准确性,对于存疑之处,标识为“待确认”,由人工确认是文本误植还是程序有误,从而起到不断校正程序和文本的效果。
三是计算机借助史书行文主体时间线一般是单调缓慢递增的特点,进行自我评价。对于有跳跃之处,由人工确认是否有误。
四是借助统计方法,计算全书所有识别结果公元年的标准差。一般来说,史书的纪年信息相对比较集中,标准差较小。对于标准差比较大的,以及偏离中位线比较远的时间点,可通过人工进行二次确认。
一般来说,纪时信息越完整,准确度越高,特别是汉以后,几乎可达100%,先秦时期因各地使用的历法有差别,这一部分数据及准确率还有待提高。因前文而从简的,准确率也相对低一些,对于有句读的历史类文本,准确率可达到95%左右。
四、应用场景
本研究所采用的技术和数据,以及纪时标签识别的成果,都可转化成应用。学者在整理或阅读文献的过程中,难免会遇到一些不确定的纪时信息,因此,可开发成工具,对学者输入的任何古代纪时文本段,转换成对应的公元纪年和夏历日期,同时把与这一日期相关的数据和资料,也一并呈现。用户也可输入一个朝代或年号,查询对应的君主列表及执政时间。把提取纪时信息的技术应用到“知识图谱网”约11,000部古籍上,可得到约743万个纪时标签。应用到诗库104万首作品上,又可得到约73万个,共超过800万个规范化后的纪时标签。这样便可对古籍库和诗库内容按纪时信息重编,为学者提供按纪时信息查询资料的服务。这在按关键词检索的平台,几乎是做不到的。正如前面所述,由于表达的灵活性,以及后文因前文而从省的情况,难以穷举某一年份或某一日期的所有的关键词。例如,宋元祐八年,即公元1093年。宋郭祥正诗《癸酉除夜呈邻舍刘秀才》,《宋史》“英宗宣仁圣烈皇后高氏,哲宗元祐八年九月三日崩于崇庆宫”[11],《续资治通鉴长编》“元祐七年,南郊赦杖罪。八年秋,皇太后服药而赦……”[12],《金史》“世祖翼简皇后,拏懒氏。大安元年癸酉岁卒”[13],以上都是指1093年。如按关键词搜索,既难以穷举各种表达方式,又需要处理很多“噪音”。通过本技术成果对这些纪时信息进行规范化之后,现在只需要输入“1093年”,便可得到所有结果。上述应用已上线,详见“知识图谱网”的“年历”功能。[14]
结 语
本研究虽已经解决了自动提取古汉语纪时实体信息的主要问题,但仍有不少待改进之处。一是并未建立历代节气与农历日期之间的对应关系,所以在规范化的过程中,未能把节气与日期联系起来;二是对于未标点化的文本,识别效果较差,将来或可结合自动标点化技术成果,进一步提升准确率;三是上下文涉及的人物信息,是年号消歧的关键,人物实体信息自动提取的准确度,势必也会影响到纪时实体信息的准确度。以上几点,仍有待后续完善。
时、地、人、事四要素,纪时信息的提取,由于其模式有规律可循,且每个组成要素的取值范围有限,从技术上来说,相对比较容易实现。本文所采用的技术,也可应用到其他实体信息的提取上。事实上,作者已把同一技术应用到地点、人物和职官等其他实体,数据及算法仍有待优化,技术成熟之后将另撰专文介绍。
Research on the Date Time Entity Extraction Model and Application in Ancient Documents
Chen Yiyun
Abstract: Extracting the ancient date time entity from Chinese ancient books is important for knowledge graph construction and application development. Yantian Zhang already detailed how ancient Chinese record the date and time in his book Zhong Guo Gu Dai Ji Shi Kao. However, there are lots of challenges when trying to design the date time entity extraction model. First, there are quite a few of variant date time schemas and appositive words. Second, the date time information usually is trimmed and simplified based on the context. So, the model must know about the context to conclude the exact date or time. Third, some date time key words are short and hard to differentiate from other meaning. This increases the complexity of disambiguation. Forth, the labelized result need properly interpret and formalize to the meta data, which computer can easily process and understand, to empower the application development. To solve all these challenges, Chinese ancient date time entity extraction model couldn’t run along. It must integrate with other labeling models to improve the labeling precision and meta data usability. The project developed by the author leverages Trie algorithm, Decision Trees and Native Bayes to implement the double-layer model. The paper details the problems and the solutions used by this project, also describes the online tools and applications as the result of this project.
Keywords: Chinese Ancient Date Time; Representation; Labeling; Knowledge Graph
(编辑:许可)
本文是国家社会科学基金重大项目“汉魏六朝文学编年地图平台建设”(19ZDA253)和国家社会科学基金项目“唐宋词语汇深度信息化处理及研究”(18XZW014)的阶段性成果。
注释:
[1]张衍田:《中国古代纪时考》,上海:上海古籍出版社,2019年。
[2]https://cnkgraph.com.
[3]饶尚宽:《春秋战国秦汉朔闰表》,北京:商务印书馆,2006年。
[4]陈垣:《二十史朔闰表》,北京:中华书局,1962年。
[5]汉语大词典编辑委员会:《汉语大词典》,上海:汉语大词典出版社,1993年。
[6]张㧑之、沈起炜、刘德重:《中国历代人名大辞典》,上海:上海古籍出版社,1999年。
[7]张廷玉等撰,中华书局编辑部点校:《明史》卷126《李文忠传》,北京:中华书局,1974年,第3743页。
[8]李延寿撰,中华书局编辑部点校:《北史》卷4《世宗宣武帝》,北京:中华书局,1974年,第131页。
[9]赵尔巽等撰,中华书局编辑部点校:《清史稿》卷6《圣祖本纪一》,北京:中华书局,1977年,第165页。
[10]萧子显撰,中华书局编辑部点校:《南齐书》卷2《高帝下》,北京:中华书局,1972年,第35页。
[11]脱脱等撰,中华书局编辑部点校:《宋史》卷123《园陵》,北京:中华书局,1985年,第2873页。
[12]李焘撰,上海师范大学古籍整理研究所、华东师范大学古籍整理研究所点校:《续资治通鉴长编》卷478《哲宗元祐七年》,北京:中华书局,2004年,第11395页。
[13]脱脱等撰,中华书局编辑部点校:《金史》卷63《世祖翼简皇后列传》,北京:中华书局,1975年,第1501页。
[14]https://cnkgraph.com/Calendar.