您正在访问旧版存档页面。This is the old version archive of our site.

国际数字人文进展研究
从近年发表的数字人文研究论文出发,勾勒它的整体研究面貌和研究框架,是一个可行的方法……
作者:王军 张力元;转自:公众号 DH数字人文
前沿动态

王 军 / 北京大学信息管理系
张 力 元 / 北京大学信息管理系
————————————————–
摘 要:从近年发表的数字人文研究论文出发,勾勒它的整体研究面貌和研究框架,是一个可行的方法。收集2016年至2018年数字人文领域的两种重要期刊和国际数字人文会议收录的约1,700篇论文作为研究文献,再从中筛选出约300篇论文做细读,并应用文献分析法,总结、归纳近三年来国际数字人文领域的研究成果,从而得到一个大致描述数字人文领域的研究框架。这个研究框架揭示了数字人文的研究层次、目标、步骤、工具与方法,可看作数字人文领域的一般方法论。该框架具有三个层次:理论探索、应用研究与技术支持。通过列举每一层次的研究热点,分析待解决的关键问题,为数字人文研究者提供参考。
关键词:数字人文 研究框架 文献分析法
————————————————–
数字人文是文理结合的产物,因其跨学科的特点,不同学科背景的学者很难在数字人文的定义、范围、理论等方面达成共识,从近年发表的数字人文研究论文出发来构建数字人文的研究框架是一个容易得到认同的方法。本文以数字人文领域最有学术影响力的两种期刊Digital Scholarship in the Humanities 与Digital Humanities Quarterly,以及数字人文国际联盟(Alliance of Digital Humanities Organizations ,简称ADHO)组织举办的数字人文大会为数据源,收集了2016年至2018年三年间所收录的论文,并选取谷歌图书Ngram Viewer 全球书籍词频统计器、中国历代人物传记资料库(China Biographical Database Project,简称CBDB)、DocuSky 数位人文学术研究平台(DocuSky Collaboration Platform)和中国历史地理信息系统(Chinese History and Geography Information System,简称CHGIS)项目为补充数据,作为本文的研究对象。在此数据基础上,本文应用文献分析法,分析与梳理近三年国际数字人文的研究问题、热点与趋势,并构造了一个数字人文研究框架,以反映国际数字人文研究的范围与内在结构。这个研究框架反映了数字人文的研究的层次、目标、步骤、工具与方法,可看作是数字人文研究的一般方法论。
一、理解数字人文
“数字人文”(Digital Humanities)这一词汇的最早出现年代已难以考证。现在学者们通常将2004 年出版的《数字人文指南》作为它在学术界确立地位的开端。[1]美国伊利诺伊大学香槟分校的Unsworth 认为数字人文的前身是1949年至1970年的“人文计算”(Humanities Computing),即“运用数字技术进行人文研究”。[2] 1940年代的电子化、1980年代的数字化,尤其是20世纪末21世纪初的网络化使得数字内容空前增长,相应的信息处理技术的快速进步,以及个人智能终端的大范围普及,带来了全社会的数字化变革。置身于这样颠覆性的学术生态变化中,传统人文学科必须也不得不做出自己的回应—数字人文。
与人文计算相比,数字人文涉及更大体量的数据,既包括数字化后的传统资料,又包括数字环境下的原生数字资源。大数据、人工智能等技术的兴起,改变了传统人文学科分析和处理资料的方法、观察和描述人类行为与社会现象的角度,以及呈现分析结果的形式。在多学科的参与下,数字人文呈现出多元化的发展态势,表现在参与学科、研究机构和人员、研究话题、数据类型、语言、载体、线上线下等方方面面,并由此产生了更大范围的学术影响力。[3]
鉴于数字人文的跨学科性质,不同学科背景的学者对数字人文有不同的理解,现有的定义多是从研究对象、研究目的、交叉学科属性等方面对数字人文的特征进行描述,难以在其本质内涵上达成共识。在此情形下,认识数字人文,还是从其发展历程来梳理较为稳妥。
针对数字人文的前身人文计算,Hockey 将其发展历程划分为1949年至1970年代、1970年代至1980年代中期、1980年代中期到1990年代早期、1990年代早期以后四个阶段。[4]2005年数字人文国际联盟的成立,标志着数字人文得到了国际学术界的普遍认可,可将此看作是数字人文作为一个研究领域得以确立的标志性事件。自此经过5年的发展,在久负盛名、规模庞大的美国当代语言协会(Modern Language Association,简称MLA)2009年会上,数字人文成为大会最热烈的讨论主题。[5]因此,本文在Hockey对人文计算阶段划分的基础上,将2005 年至今的15 年以2019 年MLA 会议为分界点划分为两个阶段:“数字人文领域的确立期”(2005—2009)和“数字人文领域的发展壮大期”(2009—2019)(见图1),这与柯平、宫平的研究[6]不谋而合。
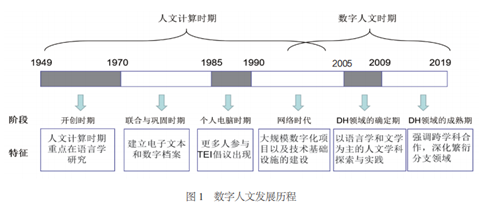
1949年至1970年代:此阶段为开创时期,人文计算兴起,研究重点在语言学研究。其间研究人员使用基于穿孔卡和磁带存储的计算机对古典文本进行语汇索引、文本字词统计等研究,并出现了计算语言学专门的机构、期刊和会议。
1970年代至1980年代:此阶段为联合与巩固时期,研究重点在于建立电子文本和数字档案工作。此阶段的计算语言类会议和期刊论文频出,计算机和人文学者之间展开了合作,致力于语料库的建设并联合开发和推广文本创建、维护和存储书面的程序。
1980年代中期至1990年代早期:个人计算机和电子邮件开始普及,为人文计算的学术社区带来了新活力,且提高了领域影响力。此阶段的代表性成果为文本编码倡议(Text Encoding Initiative,简称TEI)。
1990年代早期至21世纪早期:这是Internet 在全球范围内扩张的时代,各个学科都在经历数字化的变革,数字化的语料及分析方法在人文学科中开始被系统化地使用,“数字人文”这一概念随着John Unsworth 等人编撰的《数字人文指南》的出版开始流行,大学和研究机构开始有了专门的研究团队以及数字人文专业,这一时期的特点在于大规模数字化项目以及技术基础设施的建设。
2005年至2009年:2005年数字人文国际联盟的成立,标志着数字人文领域的正式确立。随着整个学术生态迁移到互联网环境下,数字化的人文信息资源规模不断增长,相关的学术团体启动了更为深入和成较大规模的研究项目,同时文献发表量快速增长。
2009年至今:此阶段暂时可称为“数字人文的发展壮大期”。这一时期更加强调跨学科合作,强调人文问题与数字技术的有机结合,深化繁衍分支领域,伴随研究文献的大规模增长。
二、 数字人文的研究框架
作为一个跨学科的研究领域,数字人文研究吸引了来自语言学、文学、历史、地理、计算机、图书情报学等多个学科的专家学者。比起“学科”,数字人文更接近于一个“学科共同体”,构成这一共同体的多个学科,为数字人文的研究问题贡献各自的理论、方法与工具,共同决定数字人文研究的发展方向。这一方面赋予了数字人文的多元发展动力,另一方面也使得数字人文的研究范畴有庞杂松散之嫌。已有一些学者应用文本分析、计量分析、网络分析等方法试图勾勒国内外数字人文的研究范畴和演化路径,[7]但缺少通过细读文献系统归纳近几年国际数字人文研究热点的论文。本文采用文献分析法,选取近三年数字人文领域的国际顶级期刊与会议论文作为研究对象,深入分析其研究内容与内在结构,把握最新研究动态,总结发展趋势,为国内相关研究提供参考。
本文以数字人文领域最有影响力的两种学术期刊Digital Scholarship in the Humanities 与Digital Humanities Quarterly,以及国际数字人文大会为数据源,收集它们在2016 年至2018 年三年间所收录的论文,总计约1,700篇文献,同时选取Ngram Viewer、CBDB、DocuSky、CHGIS 为补充案例。Digital Scholarship in the Humanities,简称DSH,原名为Literary and Linguistic Computing,首创于1986年,为数字人文领域内历史最为悠久且最享有盛誉的期刊之一。2016年至2018年三年间总文献数量为217篇。Digital Humanities Quarterly,简称DHQ,首创于2007年,同样为数字人文领域最具权威性的期刊之一。2016年至2018年三年间文献总数量为176篇。国际数字人文大会由ADHO 组织举办。ADHO 成立于2005年,是第一个也是最大的国际数字人文联盟组织。[8]ADHO 每年举办一次国际数字人文大会,吸引近千篇论文投稿。其每年panels、long papers、short papers、posters 等不同板块收录的总数量约为400—450篇,并会将题录数据发布在官方网站上。2016年至2018年三年间文献总数量约为1,300篇。综上,本研究所选取的研究文献总数量约为1,700 篇。
在通读这些研究文献的标题与摘要信息的基础上,选取有代表性的论文约300篇加以细读。从选中的细读论文集合中,归纳它们的研究论题与研究方法,分析其相互关系,在此基础上形成了本文的数字人文研究框架(图2)。它由三个层次构成:理论探索、应用研究与技术支持。

这个框架大致描述了国际上数字人文研究的主题分布。在较宏观的层面上, 人文学者们对数字人文的理论探索议题主要有:数字人文领域的学科构建与教学体系[9]、学术社区的形成与组织[10]、细读与遥读的阅读模式分析[11],以及未来发展方向探讨[12]。在微观的技术支持层面,数字人文领域常见的应用技术有:资料的数字化、存储与管理,自然语言处理[13],本体与关联数据[14],复杂网络分析[15],机器学习,文本挖掘,[16]可视化与地理信息系统[17]等。中间层次的应用研究在现有的数字人文研究中所占比例最大。这一类研究又可划分为三个模块:数据采集与资料库构建[18],研究工具与研究平台的建设[19],数据分析与结果解读[20]。从左向右,这三个模块顺序构成了数字人文应用研究的推进流程:数据的收集、清洗与资料库的构建是数字人文研究的基础与起点。在数字化的数据集上,直接展开各类数据分析对大多数人文学者仍是一个挑战。因此,有不少论文讨论各类研究工具和集成化分析平台,例如谷歌图书项目的Ngram Viewer ,[21]美国UIUC 开发的HathiTrust Digital Library[22],台湾大学开发的DocuSky Collaboration Platformf [23]等。也可以直接在数据集上进行数据分析,包括文本分析、网络分析、可视化分析、游戏化设计等。分析结果通常以可视化的形式展现,并且结合人文领域知识展开深入解读。
三、理论探索
(一)学科构建
随着数字人文逐步走向成熟,学科构建与综合型人才教育问题逐渐受到数字人文领域与各高校的重视。Digital Humanities Quarterly 将2017年第三季度的特别版设定为数字人文本科生教育主题。高校在数字人文教育上进展不一:初步进展有举办数字人文工作坊、暑期班和论坛等形式;进一步则会开设相应的课程,如将数字人文的内容和理念融入原有人文或信息技术类课程中,或开设独立的数字人文课程;较为成熟的则是设立数字人文主修或辅修学位等。目前数字人文教育以跨学科联合培养模式居多,所依托的学院主要有人文类学院,例如语言、历史、哲学、艺术等学院,以及信息技术类学院,例如计算机、计算语言所、图书情报等学院。
数字人文学科构建方面的文献多是分享教学经验,如以开设的数字人文课程为案例来分析教学的可行性、协作、职业发展与教学评估等。[24]此类课程通常与实际项目结合,让学生从实践中理解数字人文的意义、内容、工具,同时学生的参与也为项目提供了“众包”的价值,实现双赢。[25]也有学者从学科间关系切入进行理论分析,如英国利兹大学的Pitman 和利物浦大学的Taylor 探讨了现代语言学和数字人文之间跨学科交流的性质和特点,并充分认可了跨学科赋予数字人文的异质性。[26]
数字人文的跨学科特点与研究性给高校的学科构建与机构支持带来了新的要求和挑战。本研究列举公平性问题、文理融合问题、师资问题、评价制度问题具体讨论。
1.公平性问题:数字人文运用大量的数字资源与数字化技术,因此具有数字鸿沟问题,并且将数字鸿沟影响范围扩展到了人文领域。由于地区差异、结构失衡、教育设施不同、师资不均等问题,仅有部分地区与机构才有能力开展数字人文研究或开设数字人文课程。
2.文理融合问题:数字人文需要文理知识兼具的综合性人才,然而目前的基础教育与思维方式都是将“文”和“理”分开对待的。义务教育文理互通的趋势,以及数字人文“文理兼具”思想的渗透,都有助于解决文理鸿沟问题。课程由什么院系开设、是否需要联合培养、是否将编程融入人文课程中、所涉及技术和人文类知识讲到何种深度等问题,都需要进一步探索。
3.师资问题:数字人文是个前沿的学科,很多学校原有的课程体系并没有这方面的基础,因此引入数字人文教育对老师和学生都具有挑战性,[27]具有设计和开设数字人文课程能力的老师较少,即使开设了课程,很多老师需要一边学习数字人文的方法,一边把这些内容融入课程中教授学生,这对于没有基础的老师和学生来讲接受起来都很困难。
4.评价制度问题:数字人文研究成果的评价尚未有统一且公认的标准体系。数字人文研究项目需要前期资料收集、整理、资料库构建、系统研究平台开发等一系列大量投入精力但较难产生论文成果的工作,因此单纯选用发表论文的评价方式不适用于此类研究,应结合项目成果综合评价。合理有效的评价制度可以为数字人文学者提供激励和动力,保护其研究成果,也是对研究成果的尊重与认可。[28]
(二)社区构建
数字人文社区通常以虚拟形式存在,通过网络提供工具、软件、数据集、人才、标准、合作模式等方面的共享资源。数字人文的社区构建涉及地域和学科两个维度。跨地域强调将不同机构、地区、国家的人员和资源互联,跨学科强调将不同的学科和学科所属机构互联,目的皆在于促进思想碰撞、资源交换、资源共享。
数字人文社区构建方面的研究多为分享数字人文社区构建经验,并基于此分析社区的目标、定位、功能、成功要素等。数字人文社区的建设离不开机构的资源互联与共享,如面向欧洲文化遗产资源共享的Cultural Heritage Data Reuse Charter 在线社区链接了地方的美术馆、档案馆、博物馆、图书馆,将文化遗产数据资源共享给文化遗产机构、文化遗产实验室、研究人员、数据中心和研究机构。[29]World Views项目旨在通过增强可重用性、可发现性和可持续性,提高学者对文化、历史、数字人文研究方面的数字化教科书资源的可获取性。[30]加拿大布鲁克大学的Christie 针对数字人文的教育,提出了数字化的教学材料、使用数字人文学科工具的教学指南以及带有教学大纲模板工具的在线教学社区。[31]伦敦大学学院的Mahony 研究了数字人文社区的构建和发展的经验,认为一个良好的社区应支持学者分享信息、项目、工具、研究问题,还应提供一些指南、研讨会等信息,支持学者讨论研究,并形成新的项目伙伴关系。[32]此外,数字人文社区还需让成员们感到他们是利益相关者,培养主人翁意识,使其能够从参与和贡献中获得价值。高胜寒等人分析了国际数字人文组织联盟ADHO 和其成员子社区, 发现这些社区的主要工作是吸纳各国成员、定期举办会议、开展研究项目、编撰和出版数字人文学科期刊,以及为数字人文项目提供资金支持。[33]
但是数字人文社区的构建与运营仍存在区域性和排他性问题。例如,大学机构倾向于使用自己的工具和系统而非网上免费的开源工具,这种倾向性对构建统一的标准和社区带来阻碍。[34]目前数字人文社区主要面向英语国家的机构和学者。墨西哥RedDH 数字人文社区的成功案例可以为其他国家的数字人文社区提供参考,其构建主要关注社区渠道建立、成员定义及社区定位三个问题,[35]但是这些地方社区如何融入全球化社区还有待进一步观察。同样的问题也发生在中国,因为语言和发展阶段等问题,中国内地尚未有公认的大型数字人文社区,也未加入ADHO 等国际联盟中。因此,数字人文社区的全球化构建仍是一个需要持续探索的问题。
(三)细读与遥读
数字技术与数字人文的发展为传统人文研究带来了诸多变化,这种变化不仅表现为数字资源的量、形态、可及性方面的丰富,更表现为阅读与思考模式的转变,[36]对细读与遥读的辨析反映了学者面对这种转变的思考。
细读,指通过深度阅读来辨析字里行间的含义与逻辑,理解文本内容中不同层次的含义,达到深入理解文章内容的目的。[37]传统方式下的细读通常会运用不同颜色、形状的标记对纸质书籍文献做标注,或者在相关语句旁写下思考与总结。[38]数字人文的阅读与标注系统不仅可以电子化地实现同样的功能,还可以提供如可持续性标注、存储以及协作标注等更多功能。
遥读,强调展现文本全貌信息,突出摘要性和全局特征,常以可视化的形式呈现,如图表、树状图、地图。[39]遥读的分析方式是在宏观的层面去分析一个或多个文本的概貌,扩大了人文学者可获取与可理解的文本数量,达到“观其大略,豁然贯通”的效果。值得注意的是,人文学者认为准确的源文本非常重要,因此数字人文不应轻视细读的重要性。与其对立地看待两种阅读方式,不如将二者结合起来应用,例如可以先通过遥读宏观分析文本概貌,直观把握文本整体状态,然后选择重要的部分锁定对应的源文本细读。
(四)发展方向
数字人文的发展方向受到数字技术与人文学科发展的双重影响。就人文学科是否一定走向数字化的问题,丹麦哥本哈根大学的Roued-Cunliffe 给出了一个双重的答案:“是”是因为人文学者需要数字化工具理解在线文化和文化产品,“否”是数字化并不是人文学科的唯一出路,文化和文化产品也将继续在线下发展,传统的人文学科方法也不能舍弃。[40]美国伊利诺伊理工大学设计学院的Ruecker 认为,数字人文可以推动人文学科研究真正的人文问题,提高人文学科在研究领域的地位和影响力。[41]丹麦奥胡斯大学的Brügger 认为,传统资料的数字化转变是造成人文学科的主要变革因素之一。[42]英国伦敦国王学院的Caton 等人认为,数字人文带来了认知论上的转变,人文学者不仅需要重新思考人类意识和知识是如何构建的,也需要考虑如何在21世纪对知识文化进行重建。[43]
也有一些学者从数字人文跨学科的合作、运行和管理机制探讨数字人文的发展方向和路径。正规的合作模式和工作流程对于数字人文的研究十分重要。Caton 等人认为,数字人文研究者需要关注到工具、方法、伦理、教育、组织官僚机构、人力资源管理、经济、系统维护等方面的问题,并以伦敦大学国王学院的数字实验室为例做了详细的说明。[44]美国高等教育信息化协会分析中心的ECAR 工作组出版了一份关于加强机构对数字人文支持的白皮书,从管理、架构、角色、能力、沟通、认可度六个角度对机构支持做了分析。[45]
图书馆在数字人文的发展中扮演重要角色。柯平与宫平的研究表明,图书馆是数字人文产生的基础学科,二者都关注检索、元数据、资源描述、分类、出版与传播、开放获取、关联数据、数据挖掘、资源管理与维护等方面,只是数字人文更侧重于对人文学科信息和知识的加工和利用。[46]在机构支持中,图书馆对数字人文的支持也最为直接,同时数字人文也是图书馆自身服务转型并参与研究的重要机遇,而且数字人文的成果也可以用于完善图书馆的资源和服务。美国伊利诺伊大学的Green 等人通过采访发现,数字人文研究者对图书馆的资源与服务具有较高需求,如研究生需要图书馆在工具和软件上提供支持,教师的需求则侧重于提供专业知识、协助访问数字内容、数据存储等方面。同时,为了提高图书馆与数字人文研究之间互动的效果,研究人员应该更主动去应用图书馆资源并提出对资源的需求,图书馆也应为馆员提供深度培训,增强馆员获取数字馆藏和信息组织的能力,且多鼓励馆员主动与科研人员接触,提高其数字人文服务能力。此外,图书馆应在数据资源长期保存管理和建立数字人文实践社区上做出贡献,进而成为数字人文研究活动网络的关键节点。[47]
四、应用研究
数字人文的应用性研究的内容范围非常广泛,具有强烈的地域、学科、方法等方面的差异,导致研究问题繁多复杂,难以在内容层面梳理概括。虽然这些研究的对象与内容各有不同,但都符合数字人文的研究流程。具体来看,数字人文的研究流程起始于收集与存储数据,并据此构建资料库,在此基础上可以构建检索浏览或研究平台等工具,也可以直接对数据进行研究分析,最终以可视化或其他方式呈现分析结果。在这样的流程下,具体的应用研究问题便可以对应于流程中的不同阶段与步骤。因此,本文根据数字人文应用研究流程梳理相关文献,在此基础上选取数据集构建、资料浏览与分析平台构建以及文本分析作为代表性研究热点详细介绍。
(一)数据集构建
数据集的构建位于数字人文应用研究流程的基础阶段,目的是实现资料的电子化,并以数据库等形式存储。图书馆、档案馆与博物馆因具有天然的数据积累优势,通常是数据集构建的主体机构,进行纸本数据的电子化及信息组织工作。数字人文数据以文本形式为主,兼有图片、音频、视频、3D 等多元数据形式。文本资料有地方古典文本资料、图书、笔迹、家谱资料等。图片有地图、画作、壁画等。3D 数据有文物、器皿、雕塑等。音频与视频数据包括访谈、纪录片等多媒体数据。数字人文数据集内容覆盖广泛,因项目资源和人力分布的不同而具有很强的地方文化特征。例如中国历代人物传记资料库记录了中国历代约42.26 万人物的信息,[48]荷兰民俗数据库记录了上万个荷兰的民俗故事。[49]
纸本数据有手写体和印刷体版本,电子化方法主要依赖于OCR 与机器学习技术,以实现扫描与识别任务。例如,德国的Springmann 和Lüdeling使用基于神经网络的OCR 扫描1487 年至1870 年间印刷的书籍影像,[50]比利时的Kestemont 和法国的Stutzmann 使用卷积神经网络对中世纪拉丁手稿进行手迹识别,[51]瑞士的Oliveira 等人提出了可以自动分割和解释19 世纪初威尼托地区的拿破仑卡德斯地图的机器视觉算法,提取出每个碎片的几何图形,并对手写的标签进行分类、读取和解释。[52]
众包也是数据集构建中常用的方法,常应用于语料库的标注等需要大量人工参与的基础性文本处理的项目。众包的参与者有领域专家、学生和普通志愿者。采用众包的方式可以在很大程度上提高项目推进的效率,但是也面临因参与者完成质量的差异而带来对准确性和可靠性的质疑。伦敦大学学院的Causer 等人选取了Transcribe Bentham 众包转录项目作为案例,以众包的费用、核查的时间、参与者工作的质量为评价指标对众包参与者的贡献价值、众包转录的经济价值、投资与回报进行了讨论。[53]利用标注平台是推进众包工作的一种有效方式,常见的标注平台有MARKUS、Hypothes.is、eMargin 等。例如美国塔夫茨大学的Beaulieu 等人在教学活动中让学生使用Hypothes.is 开源标注平台进行词典标注, 这个工具虽然不提供受控词表,但是具有很好的通用性,例如它支持任意形式的文本和标签输入,适用于任意网站,且提供检索标注的API。[54]
(二)资料浏览与分析平台构建
在数据集的基础上,很多项目会进一步构建面向用户的数据检索与浏览平台,实现电子资料的开源分享,扩大资料的可及性,增强研究和教育价值。这样的资料检索与浏览平台与图书馆所提供的书目检索与浏览系统相似,因此也常由图书馆来完成平台构建工作。与图书馆在提供图书资料查询服务的基础上提供知识服务相似,除了基础的资料检索与浏览功能外,这类研究项目还常常会提供资料分析功能。如果检索与浏览对应于细读,那么分析具对应用于遥读。鉴于人文学者对资料准确性的要求,在浏览平台提供原始资料的扫描图像会增加可信性。
分析平台会提供诸如基础统计分析(例如字频、词频统计)、GIS 地理信息呈现、社会网络分析等功能,使用户可以对特定文本进行分析和可视化探索,具有较强的交互属性。代表性项目有Francois 等人合作创建的全球历史项目Seshat, 收录了人类社会、政治和文化的历史数据并提供分析功能辅助用户从数据中挖掘有用信息。[55]台湾法鼓文理学院图书资讯系开发的CBETA 数位研究平台,提供对佛典资料的检索、浏览功能,此外还提供字频词频统计、关键字词前后文统计、佛学字典、GIS 地理信息可视化等辅助分析功能。[56]
资料分析功能也可以独立于数据作为单独的分析模块,支持用户利用自己的数据进行分析。这种资料分析平台支持用户上传本地数据或者从其他数据源在线将数据导入到分析平台,存储在平台云端,进而使用平台的分析工具。例如台湾大学数位人文研究中心与资讯工程学系开发的DocuSky 数位人文学术研究平台,支持用户对自己的数据进行个性化探索。[57]
资料浏览与分析平台通常以用户为中心构建,目的在于为数字人文学者提供直观且易操作的检索、浏览、分析、可视化工具。因此,用户研究在平台的设计中十分重要。例如在2014 年的英国历史在线网站(British History Online,简称BHO)重建项目通过线上用户调查收集了历史学家和系谱学家对数据集内容的偏好、常见的搜索和浏览行为、对新导航选项的接受程度等信息,并以此为基准调整网站设计架构。[58]Muiser 等人为荷兰民俗故事数据库设计使用界面时,首先定义了数据库用户,即民俗专家和普通用户,然后针对目前在线文化遗产类系统中常见的缺乏可及性、浏览探索的功能有限、不重要的内容被忽略等问题,重新设计了荷兰民俗数据库的界面,以改善民俗专家和普通用户的浏览和探索体验。[59]
(三)文本分析
数字人文领域的数据类型以文本数据为主,而这些文本数据多为文化遗产精华,故不论从数量还是重要性上讲,对文本的分析皆是数字人文应用研究的重点。文本分析是对文本数据的加工和处理,提取有用的知识,以解答相应的研究问题。文本分析包括了文本相似性比较、作者归属、作品体裁和风格比较等问题。
文本相似性比较包括文本重用鉴定及版本比较问题。人文学者比较关注文献询证,因此会提出文本重用、引用、再版、作者与文体识别等研究问题。研究方法包括OCR、命名实体识别、统计模型、多层级引文网络、自然语言处理、序列比对等。[60]相关研究有Bizzoni 等人研究现代语言对古典语言的借鉴情况, [61]Sturgeon 识别中国古籍的文本重用现象并将此技术应用于CTEXT 中国文本项目在线平台等。[62]相似的研究还有比较不同版本的出版物的差异,如比较《傲慢与偏见》全文与简化版的难易度和词频差异性,或是结合定性与定量方法比较《火星救援》原版和再版的差异,或是对《科学怪人》的多个版本进行比较等。[63]
作者归属与体裁判断是计量文体学的问题。很多文本资料年代久远,难以考证作者信息,但是可以借助数字方法定量分析文本,以此为依据鉴别作者。例如16 世纪至17 世纪中叶的英国,由于标题页上的出版信息错误或没有记录合著者等因素,很多剧本难以判定作者。针对这一问题,宾夕法尼亚大学的Eisen 等人用相对熵来计算6 位戏剧作者的戏剧作品集之间的相似性,然后对每个戏剧构建功能词邻接网络来分析作者归属。[64]波兰的Eder 经实验发现,通常2,000 字的文本规模就足以识别作者身份。[65]德国的Tello 等人利用Delta 测距的方法来分析不同作者的文本文体的亚流派特征。[66]
五、技术支持
(一)语义技术
数字人文研究中的语义技术主要有关联数据和本体构建。语义技术可对数据存储、整合、处理、展示,挖掘数据间内在逻辑关系,进而提供相应的信息与知识服务。
关联数据在数字人文领域得到广泛的关注和应用,如果数据资源是开放的, 则可称为关联开放数据(Linked Open Data,简称LOD),如DBpedia。LOD 开放且非中心化的数据表示模型可以促进知识关联,而且可以通过互链和统一视图将不同的数据透视图合并,进而整合多种资源。如“欧洲数字手稿项目”和“关联人文项目”皆旨在利用关联数据技术整合多源异构数据,并开发相应的数据浏览 与分析工具,提高数据的共享与重用率,进而服务于人文研究。[67]
“本体”是共享概念模型的明确的形式化规范说明。[68]为大型数据资源构建本体,可以用语义化形式存储与利用文本,可实现推理功能,辅助复杂语义检索。目前主要有两种方式构建本体:自上而下,即由专家构建本体,或自下而上,即由数据聚类得到。数字人文领域关于本体的研究主要有:扩展或改造已有本体模型使其适合研究领域与研究问题,或创建辅助用户构建本体的工具。例如,在文化遗产领域本体构建方面,Kyvernitou 和Bikakis 提出了融入性别概念的本体架构,他们在欧洲数据模型的基础上新增了22 个类,16 个实体属性,7 个数据类型属性,构建了GenderedCHContents 本体。[69]针对本体构建的复杂性问题,德国的Kräutli等人根据CIDOC-CRM 这样一个在文化遗产及博物馆档案方面的扩展领域本体模型构建了一个CorpusTracer 前端系统,以方便用户创建和查询关联数据而无须担心复杂的编码。[70]OWLnotator 是一个本体构建标注工具,可应用于跨多媒体语料的标注任务。它提供了一个通用的图形化网页界面,该界面显示底层本体的可用类和属性,与ResourceManager 联合使用可以将不同类型的资源分配到对应的本体。[71]
基于本体的语义技术可以支持丰富的文本处理和展现功能,还可以检测和补充缺失数据。以色列的Prebor 等人针对含有缺失数据的希伯来人历史手稿目录提出了一个结合事件本体与网络分析的方法,可以检测、补充缺失值,并修改相应的错误,包括如下几个步骤:对本体实体的抽取与构建、基于本体间的直接和间接联系构建实体网络、网络的自动社区探测、离群值检测,以及基于网络中本体的关系和社区的半自动缺失数据推测。[72]
(二)自然语言处理
自然语言处理技术是利用语言学知识和计算机技术处理文本或语音数据,目的在于提升计算机理解和处理人类自然语言的能力。目前自然语言处理的几种常见方法有基于规则和模式匹配、基于统计机器学习和基于深度学习。数字人文的主要研究对象是文本数据,因此利用自然语言处理技术处理文本数据是非常重要的研究,包括词法分析、句法分析、语义分析、语用分析等,例如对字、词、句的识别和处理,实体、关系、事件等信息抽取,或情感分析。
字、词、句的识别与处理是将纸本数据数字化时首先需要解决的问题,其效果直接影响到后续文本分析的准确率和召回率。OCR 技术对印刷版文字的识别效果较好,可以达到与人工相近的准确率,[73]而对手写体文字的识别效果则一般。神经网络因对特征采集的多样性和灵活性在OCR 处理手写体问题中受到了很高的关注。[74]例如瑞士的Oliveira 和Kaplan 使用CRNN 技术识别18 世纪的威尼斯财政手写文件,并与人工的准确率做比较,发现CRNN 技术的准确率比业余标注者的准确率高。[75]针对OCR 可能出现的拼写识别错误问题,伊朗的Dashti 等人提出了一种基于统计和句法规则的混合模型,可自动校正OCR 识别结果。[76]基于神经网络的模型训练需要大量的标注数据集,美国圣母大学的Grieggs 等人开发了一个标注工具,用户可以精准切割与标注手写体文本图像,还可以对每个字的识别难易程度打分,标注结果也可以以TEI 形式导出。[77]
自然语言中的信息抽取包括实体、关系、事件的抽取,目前在数字人文领域中以命名实体抽取为主,也就是对地名、人名、组织名的识别。信息抽取的结果可以直接构建数据库,也可以进一步构建知识图谱。研究表明,即便在OCR 效果一般的情况下,仍可以得到准确率还不错的信息抽取结果。[78]
情感分析主要是分析、处理、归纳和推理带有情感色彩的文本中的观点、情感、态度和情绪。[79]借助情感分析来推断文本中包含的情感类语义信息可以提高对文本的深入理解能力。情感维度有多种划分方式,例如,可以按照情感极性划分为正、负、中性,也可以按照情绪划分为信任、恐惧、高兴等,并可以用量表刻画每种情绪的强烈程度。现有的情感分析技术常应用在现代文语料中,例如对twitter、微博等社交媒体的情感挖掘分析,而缺少对历史语料的情感分析。而数字人文又以历史文本为主,因此需要改进情感分析方法使其适合相关研究。荷兰Leemans团队的项目“Embodied Emotion”构建了针对历史文本的情感挖掘模型HEEM,用来挖掘文本语料库的情感,并追踪这种情感的历史演变轨迹。[80]德国Buechel 团队提出了更适合数字人文研究的VAD(Valence-Arousal-Dominance) 三维立体情绪模型,以表达更多的情感信息。[81]
(三)文本挖掘
文本挖掘,即文本数据挖掘,文本知识发现,是从文本数据中挖掘出隐含的、潜在有用的模式,进而发现知识的过程。[82]文本挖掘与自然语言处理都是从大规模的文本数据中提取特征模式,具有很多共同的方法。二者的区别主要在于,文本挖掘是面向人的,其抽取出的知识是人可以直接使用的,而自然语言处理是面向计算机的,目的在于加强计算机对自然语言的理解。文本挖掘可以直接面向文本研究,也可以在自然语言处理的成果上展开深入的研究。简单的文本挖掘方法包括统计字频和词频,复杂的文本挖掘方法包括文本聚类、主题模型、关联分析、预测等。
文本聚类是一种无监督的文本自动分类方法,可用于信息检索和主题发现。主题模型是大规模文本语料主题分析的常见方法,LDA(隐狄利克雷模型)是目前最常用的主题模型之一。主题模型可以呈现文本的整体情况,增加时间维度则可以分析文本的主题演变,属于遥读方式。通过一些成熟的算法和开源包,例如基于Java 的MALLET 和基于Python 的Gensim 库,可以从大规模文本中抽取主题,概览文本资料。[83]如西班牙的Garcia-Zorita 和Pacios 利用MALLET 工具对西班牙1857 年至2013 年间2,454 份关于Mudejar 艺术的文献标题进行了粗(5 类)、细(10 类)粒度的LDA 聚类分析,并结合领域专家人工判读来分析西班牙艺术史主题分布。[84]美国的Garcia 利用MALLET 工具对美国1776 年至1820 年间的殖民者通信记录、政府文件、政治精英的写作进行LDA 聚类分析,研究美国早期殖民情况。[85]德国的Schöch 使用主题模型分析法国古典时代和启蒙运动的戏剧文本的体裁类型。[86]
例如MALLE 与Gensim 这样的工具增加了文本分析的便利性,但仍需一定的编码技能,因此具有使用门槛。针对这一问题,德国的Pielström 等人开发了一个无须编码的工具,支持用户导入源文本并生成可视化主题分布结果,并且可以自定义停用词词表、高频词阈值、主题个数以及算法迭代次数。[87]可视化展现主题模型的结果,可以让复杂的结果变得更加直观易理解,增加可读性与可解释性。
也有学者表达了对单纯依靠主题模型理解文本内容的担忧,提出遥读与细读应该结合使用,如美国纽约大学的Armoza 开发的Topic Words in Context 软件, 同时支持多种模式的细读与遥读,强调主题模型不离实际文本内容。[88]
(四)社会网络分析
社会网络是社会的行动者及其关系的集合,社会网络分析对这些关系建模, 通过网络描述群体关系结构,并且研究这种结构对群体功能或者群体内部个体的影响。[89]社会网络分析具有跨学科研究性质,和物理学、社会学、情报学等领域都有交集。在数字人文研究中,社会网络分析以人物及人物关系为主要研究对象。除了研究静态的关系网络外,还可以引入时间维度,利用网络分析研究群体变迁的历时性过程。
常见的社会网络分析工具有Gephi、Ucinet、Pajek 等,均可绘制社会关系网络,并提供图密度、中心性、平均聚集系数等指标分析网络结构与特征。数字人文领域中较为常见的一个分析角度是从传记或小说类文学文本中提取人物和关系构建社会网络,再现文学中人物的世界。例如美国斯坦福大学的Edmondson用社会网络分析方法分析了科林小说里女主角科林的社会网络,进而分析她在小说里的社交活动是如何对现实中的女性解放启蒙运动造成影响的。[90]德国的Jänicke 与Focht 使用社会网络分析可视化地展现了音乐家的师徒关系,[91]以此研究音乐领域中的“创造性转移”问题。[92]
社会网络分析也可以帮助判断文学风格和体裁。例如加拿大的Evalyn 等人构建了37 部莎士比亚戏剧中人物的交流关系网络,并依据网络分析指标来判断喜剧、悲剧与历史剧等体裁。[93]
(五)可视化与 GIS
可视化是利用计算机图形图像处理技术分析与探索数据集,直观展示结果并反映研究主题和意图的方法。这不仅可以提高研究者自身理解研究结果的能力, 获得隐性的知识,也有助于将研究成果直观展现给读者并与读者交流。除可以辅助研究外,可视化自身也具有一定的美学价值。[94]
常见的可视化工具有Echarts、D3.js、Shiny 与Tableau等。可视化往往不是单独存在的,而是与主题模型、社会网络分析、地理信息系统GIS 等相结合使用的,用来呈现分析结果,以取得更为直观、易理解且有冲击力的视觉效果。很多学者应用可视化的方法分析大规模图像数据,如Ferguson 选择了迪士尼动画电影语料库为研究对象,[95]Jeong 和Han 选择了不同国家亚马逊网站的前100 张畅销书封面为研究对象,[96]Tran 等人选择了历史上知名画家的作品并以调色板图谱的形式比较作品风格差异性。[97]
地理信息系统GIS 是地图形式的可视化,为人物和事件赋予地理坐标,将信息可视化展现在地图上。静态GIS 可以呈现一些简单且固定的信息,动态GIS 可以模拟人类行为。[98]经典项目有哈佛大学与复旦大学联合开发的中国历史地理信息系统项目,并支持统计功能和查寻功能。[99]在GIS 平台的基础上还需要不断丰富和完善地理图层,如加拿大的Jenstad 等人结合GIS 工具和伦敦地名辞典数据, 绘制英语图书贸易地图的GIS 图层。[100]
(六)机器学习
机器学习被广泛应用于数字人文的研究中,例如利用机器学习进行OCR 手写体的识别,进行字、词、句的自然语言处理。但由于机器学习常与其他方法结合应用,因此在此不单独列举机器学习的内容。
六、研究趋势总结
数字人文发展迅速,参与研究的学科也很多。执着于辨析数字人文领域究竟是不是一个独立的学科只会徒增困惑,因为,数字人文的特质正在于突破原有的学术藩篱与组织边界。[101]相关学科共同塑造了如今的数字人文研究,共同影响着数字人文研究的未来走向。
研究发现,国际数字人文研究大体上可以分成理论探索、应用研究、技术支持三个层面,包括数字人文学科构建、学术社区构建、细读与遥读模式、未来发展方向、数据集的构建与处理、数据分析平台构建、文本分析、语义技术、自然语言处理、文本挖掘、社会网络分析、可视化与GIS 等热点内容。基于此,本研究构造了一个数字人文的研究框架,以反映国际上数字人文的研究概貌。
虽然难以明确界定数字人文的学科范畴,但就研究现状来看,当前的数字人文研究在很大程度上受到四大主体学科群的影响:(一)依托传统人文学科为主体,此类研究侧重于对传统人文研究问题和方法的突破与创新,大多应用较基础的数字人文工具,以丰富的人文背景知识和深入的分析解读见长。(二)依托图书馆、博物馆、档案馆为主体,此类研究侧重于数字化资料与资料库的构建,提供知识管理和知识服务,凭借该主体所拥有的丰富数据资源来构建数据库,打造数据平台以供数字人文的学者们使用。(三)依托情报学和传播学为主体,前者侧重从技术应用、方法创新、流程梳理等方面来分析与挖掘人文语料,后者侧重于研究新媒体环境下信息传播、人群影响、数字文化等议题。二者都重视用户研究与用户体验。如果说传统人文学科所关心的问题是传统人文研究在数字环境下的延续,这二者更关注的是数字环境中所滋生的人文问题。(四)依托信息科学为主体,此类研究侧重在对算法改进、技术应用和工具开发方面,为数字人文的研究问题提供工具库和技术解决方案。
综合近三年的数字人文研究成果,我们可以观察到如下的发展趋势:首先, 数字人文研究将更加多元化,更密切地在学科间互动,并推进到更细化的分支领域。这些领域将为数字人文贡献更多元化的数据,增添更多的人力资源、支撑理论和技术方法。跨学科、跨机构、跨地域间的联系将更为密切,实现数据、人力、技术、工具、经验等资源的多元联动。毫无疑问,研究成果和文献产出也将进一步增长。其次,高校等研究机构将投入更多资源推动数字人文研究,如举办工作坊、设置专门的课程或学位、建设数字人文研究中心等。数字人文研究会得到更多资金、场所、制度等方面的支持。图书馆也将提高数字人文的服务能力, 与数字人文学者的互动会更为密切,成为数字人文活动网络的关键节点。再次, 人文与技术的结合将更为紧密,催生出更深入且有价值的成果。技术将持续更新,且更符合人文学者的行为习惯,会有更多学科的技术与方法输入到数字人文研究中。最后,理论和方法将会持续完善,包括对数字人文在哲学层面的探讨, 数字环境下人文研究范式的创新等。在此过程中将形成新的学术评价体系与相应的学科制度,加速数字人文研究的成熟,并获得更大、更持久的影响力。
—————————————————————————————————————————————————————————————
The Study of the Research Progress of International Digital Humanities
WangJun, Zhang LiyuanAbstract: It is a feasible method to outline the overall research status and framework of digital humanities based>Digital Scholarship in the Humanities and Digital Humanities Quarterly, and the international Digital Humanities conference, as data sources, and from which we choose about 300 papers for further text analysis, we can sort out and summarizes the research achievement of international digital humanities studies in the past three years, and obtains a research framework that can roughly describe digital humanities. This research framework reveals the research level, research objective, research steps, research tools and methods of digital humanities, which has certain generality to the research questions of digital humanities. The research progress of international digital humanities in recent years is divided into three levels: theoretical exploration, applied research and technical support. By devoting to enumerating the research hotspots at each level and analyzing the key problems to be solved, we can provide references for Chinese digital humanities researchers. Keywords: Digital Humanities; Research Framework; Documentary Analysis
—————————————————————————————————————————————————————————————
编 辑 | 严程 彭丹华
注释:
[1] See Susan S. , R. Siemens and J. Unsworth, A Companion to Digital Humanities, Oxford: Blackwell, 2004.
[2] See Susan S. , R. Siemens and J. Unsworth, A Companion to Digital Humanities.
[3] 参见徐力恒、陈静:《我们为什么需要数字人文》,《社会科学报》2017年8月24日,第5版;林富士:《数位人文学白皮书》,台北:中研院数位文化中心,2017年。
[4] See Susan S. , R. Siemens and J. Unsworth, A Companion to Digital Humanities.
[5] See Howard J. ,“The MLA Convention in Translation,”The Chronicle of Higher Education, Dec 31th, 2009.
[6] 参见柯平、宫平:《数字人文研究演化路径与热点领域分析》,《中国图书馆学报》2016年第6期,第13—30页。
[7] 参见柯平、宫平:《数字人文研究演化路径与热点领域分析》,《中国图书馆学报》2016年第6期;沈振萍、黄水清:《我国数字人文研究脉络及其在图书馆学情报学领域的典型应用》,《大学图书馆学报》2017年第6期;高胜寒、赵宇翔、朱庆华:《国内外数字人文领域研究进展分析》,《图书馆杂志》2016年第10期;陈光华、吴孟家:《数位人文科学语汇之生成与使用》,第九届数位典藏与数位人文国际研讨会会议论文,台北,2018年;X. Wang and M. Inaba, “Analyzing Structures and Evolution of Digital Humanities Based on Correspondence Analysis and Coword Analysis,” Art Research, vol. 3 (2009).
[8] 参见林富士:《数位人文学白皮书》。
[9] See C. Christian-Lamb and A. H. Shrout, “Starting from Scratch’? Workshopping New Directions in Undergraduate Digital Humanities,” Digital Humanities Quarterly, vol. 11, no. 3 (2017); K. Rogers, “Humanities Unbound: Supporting Careers and Scholarship beyond the Tenure Track,” Digital Humanities Quarterly, vol. 9, no. 1 (2015); S. Kelley, “Getting on the Map: A Case Study in Digital Pedagogy and Undergraduate Crowdsourcing,” Digital Humanities Quarterly, vol. 11, no. 3 (2017); K. Kennedy, “A Long- belated Welcome: Accepting Digital Humanities Methods into Non-DH Classrooms,” Digital Humanities Quarterly, vol. 11, no. 3 (2017).
[10] See A. Baillot, “Puren M, Riondet C. Access to Cultural Heritage Data: A Challenge for Digital Humanities,” Digital Humanities Conference, 2017; S. Hennicke, L-L Stahn and E. W. De Luca, et al.,“WorldViews: Access to International Textbooks for Digital Humanities Researchers,” Digital Humanities Conference, 2017; A. Christie, “Building a Toolkit for Digital Pedagogy,” Digital Humanities Quarterly, vol. 11, no. 3 (2017); S. Mahony, “The Digital Classicist: Building a Digital Humanities Community,” Digital Humanities Quarterly, vol. 11, no. 3 (2017).
[11] See S. Jänicke, G. Franzini and M. F. Cheema,et al., “On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges,” Eurographics Conference on Visualization (EuroVis)-STARs, 2015; F. Moretti, Distant Reading, London: Verso Books, 2013; F. Moretti, Graphs, Maps, Trees: Abstract Models for A Literary History, London: Verso Books, 2005.
[12] See S. Ruecker, “How Do We Get to the Humanitarium from Here?” Digital Humanities Quarterly, vol.10, no.3(2016); N. Brügger, “Digital Humanities in the 21st Century: Digital Material as a Driving Force,” Digital Humanities Quarterly, vol. 10, no. 3 (2016); D. Quinn and L. Joan, “A Capacity Building Framework for Institutional Digital Humanities Support,” Digital Humanities Conference, 2017; H. Green, E. Dickson and Tracy D, et al., “Building a Bridge to Next Generation DH Services in Libraries with a Campus Needs Assessment,” Digital Humanities Conference, 2018; A. Keener, “The Arrival Fallacy: Collaborative Research Relationships in the Digital Humanities,” Digital Humanities Quarterly, vol. 9 no. 2 (2015).
[13] See S. A. Oliveira and F. Kaplan, “Comparing Human and Machine Performances in Transcribing 18th Century Handwritten Venetian Script,” Digital Humanities Conference, 2018; S. M. Dashti, A. Khatibi Bardsiri and V. Khatibi Bardsiri, “Correcting Real-word Spelling Errors: A New Hybrid Approach,” Digital Scholarship in the Humanities, vol. 33, no. 3 (2018); K. Kettunen,E. Mäkelä and T. Ruokolainen, et al.,“Old Content and Modern Tools-searching Named Entities in a Finnish OCRed Historical Newspaper Collection 1771-1910,” Digital Humanities Quarterly, vol. 11, no. 3 (2017); I. Leemans, V. D. J. M. van der Zwaan, I. Maks, et al., “Mining embodied emotions: A comparative analysis of sentiment and emotion in Dutch texts, 1600-1800,” Digital Humanities Quarterly, vol. 11, no. 4 (2017).
[14] 参见K. Baierer, E. Dröge and K. Eckert, et al., “DM2E: A linked Data Source of Digitised Manuscripts for the Digital Humanities,” Semantic Web, vol. 8, no. 5 (2017); 夏翠娟、张磊:《关联数据在家谱数字人文服务中的应用》,《图书馆杂志》2016年第10期;I. Kyvernitou and A. Bikakis, “An Ontology for Gendered Content Representation of Cultural Heritage Artefacts,” Digital Humanities Quarterly, vol. 11, no. 3 (2017).
[15] See Evalyn L, Gauch S and Shukla M, “Analyzing Social Networks of XML Plays: Exploring Shakespeare’s Genres,” Digital Humanities Conference, 2018; C. Edmondson, “An Enlightenment Utopia: The Network of Sociability in Corinne,” Digital Humanities Quarterly, vol. 11, no. 2 (2017); S. Jänicke and J. Focht: “Untangling the Social Network of Musicians,” Digital Humanities Conference, 2017.
[16] See R. Rehurek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora,” In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, 2010; Garcia-Zorita C. and Pacios A. R., “Topic Modelling Characterization of Mudejar Art Based on Document Titles,” Digital Scholarship in the Humanities, vol. 33, no. 3 (2018); C. Schöch, “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama,” Digital Humanities Quarterly, vol. 11, no. 2 (2017).
[17] 参见刘炜、叶鹰:《数字人文的技术体系与理论结构探讨》,《中国图书馆学报》2017年第5期;Hinrichs U. and Forlini S., “In Defense of Sandcastles: Research Thinking through Visualization in DH,” Digital Humanities among Bestsellers in Different Countries,” in Proceedings of the 78th ASIS&T Annual Meeting: Information Science with Impact: Research in and for the Community, 2015, p. 107.
[18] See I. Muiser,M. Theune and R. De Jong,et al., “Supporting the Exploration of Online Cultural Heritage Collections: The Case of the Dutch Folktale Database,” Digital humanities quarterly, vol. 11, no. 4 (2017); U. Springmann and A. Lüdeling, “OCR of Historical Printings with an Application to Building Diachronic Corpora: A case Study Using the RIDGES Herbal Corpus,” arXiv preprint arXiv:1608.02153, https://arxiv.org/ pdf/1608.02153.pdf, Aug 1st, 2019; S. A. Oliveira , F. Kaplan and di Lenardo, “Machine Vision Algorithms on Cadaster Plans,” Digital Humanities Conference, 2017.
[19] 参见P. Francois, J. Manning and H. Whitehouse,et al., “A Macroscope for Global History Seshat global History Databank: a Methodological Overview,” Digital Humanities Quarterly, vol. 10, no. 4 (2016); A. Crymble,“Digital Library Search Preferences Amongst Historians and Genealogists: British History Online User Survey,”Digital Humanities Quarterly, vol. 10, no. 4 (2016); “DocuSky 数位人文学术研究平台”,网址为:http://docusky.org.tw/DocuSky/ds-01.home.html.
[20] See R. Cordell and D. Smith, “What News is New: Ads, Extras, and Viral Texts on the Nineteenth-century Newspaper Page,” Digital Humanities Conference, 2017; C. Cooney and C. Gladstone, “Tracing Swerves of Influence: Text Reuse and the Reception of Lucretius in 18th-Century England,”Digital Humanities Conference, 2017; G. Franzini and M. Büchler, “Orosius’Histories: A Digital Intertextual Investigation into the First Christian History of Rome,” Digital Humanities Conference, 2017; M. Romanello, “Exploring Citation Networks to Study Intertextuality in Classics,” Digital Humanities Quarterly, vol. 10, no. 2 (2016).
[21] Zeng R. and Greenfield P. M., “Cultural Evolution over the Last 40 Years in China: Using the Google Ngram Viewer to Study Implications of Social and Political Change for Cultural Values,” International Journal of Psychology, vol. 50, no. 1 (2015); S. Roth, “Fashionable functions: A Google ngram view of trends in functional differentiation (1800—2000),” Politics and Social Activism: Concepts, Methodologies, Tools, and Applications, IGI Global, 2016.
[22] See H. Christenson, “HathiTrust,” Library Resources & Technical Services, vol. 55, no. 2 (2011), pp. 93-102; S. Lee, “Searching the Silence: Women Writers and Romance Fiction in HathiTrust,” MLA 2019, 2019.
[23] 参见“DocuSky 数位人文学术研究平台”;S. Wang, P. Belouin and S-P Chen, et al.,“Research Infrastructure for the Study of Eurasia (RISE): Towards a Flexible and Distributed Digital Infrastructure for Resource Access via Standardized APIs and Metadata,”9th International Conference of Digital Archives and Digital Humanities, 2018.
[24] See C. Christian-Lamb and A. H. Shrout, “‘Starting from Scratch’? Workshopping New Directions in Undergraduate Digital Humanities”; K. Rogers, “Humanities Unbound: Supporting Careers and Scholarship beyond the Tenure Track”; A. Mauro, D. Powell and S. Potvin, et al., “Towards a Seamful Design of Networked Knowledge: Practical Pedagogies in Collaborative Teams,” Digital Humanities Quarterly, vol. 11, no. 3 (2017).
[25] See S. Kelley, “Getting on the Map: A Case Study in Digital Pedagogy and Undergraduate Crowdsourcing”; K. Kennedy, “A Long-belated Welcome: Accepting Digital Humanities Methods into Non-DH Classrooms”; R. K. Schindler, “Teaching Spatial Literacy in the Classical Studies Curriculum,” Digital Humanities Quarterly, vol. 10, no. 2 (2016); J. Jenstad,K. Mclean-Fiander and K. R. Mcpherson, “The MoEML Pedagogical Partnership Program,” Digital Humanities Quarterly, vol. 11, no. 3 (2017); B. Croxall, “Digital Humanities from Scratch: A Pedagogy-driven Investigation of an In-copyright Corpus,” Machine Learning, vol. 42 (2017).
[26] See T. Pitman and C. Taylor, “Where’s the ML in DH? And where’s the DH in ML? The Relationship Between Modern Languages and Digital Humanities, and an Argument for a Critical DHML,” Digital Humanities Quarterly, vol. 11, no. 1 (2017).
[27] See P. E. D. L. Monteros, J. Sadvari and M. Scheid, “Pontes into the Curriculum: Introducing DH Pedagogy through Global Partnerships,” Digital Humanities Conference, 2018, p. 571.
[28] 参见林富士:《数位人文学白皮书》。
[29] See A. Baillot, “Puren M, Riondet C. Access to Cultural Heritage Data: A Challenge for Digital Humanities.”
[30] See S. Hennicke, L-L Stahn and E. W. De Luca, et al., “WorldViews: Access to International Textbooks for Digital Humanities Researchers.”
[31] See A. Christie, “Building a Toolkit for Digital Pedagogy.”
[32] See S. Mahony, “The Digital Classicist: Building a Digital Humanities Community.”
[33] 参见高胜寒、赵宇翔、朱庆华:《国内外数字人文领域研究进展分析》,《图书馆杂志》2016年第10期。
[34] See A. Bretz, “The New Itinerancy: Digital Pedagogy and the Adjunct Instructor in the Modern Academy,” Digital Humanities Quarterly, vol. 11, no. 3 (2017).
[35] See I. G. Russell,“Creating a Regional DH Community—A Case Study of the RedHD,”Digital Humanities Quarterly, vol. 9, no. 3 (2015).
[36] See S. Jänicke, G. Franzini and M. F. Cheema, et al., “On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges.”
[37] See N. Boyles, “Closing in on Close Reading,” On Developing Readers: Readings from Educational Leadership, 2012, pp. 89-99; Jasinksi J, Sourcebook on Rhetoric: Key Concepts in Contemporary Rhetorical Theory, Ca: Sage, 2001.
[38] See S. Jänicke, G. Franzini and M. F. Cheema, et al., “On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges.”
[39] See F. Moretti, Distant Reading; F. Moretti, Graphs, Maps, Trees: Abstract Models for A Literary History.
[40] See H. Roued-Cunliffe, “The Digital Future of Humanities through the Lens of DIY Culture,” Digital Human- ities Quarterly, vol. 10, no. 4 (2016).
[41] See S. Ruecker, “How Do We Get to the Humanitarium from Here?”
[42] See N. Brügger, “Digital Humanities in the 21st Century: Digital Material as a Driving Force.”
[43] See P. Caton, G. Ferraro and L. Figueira, et al., “Mechanizing the Humanities? King’s Digital Lab as Critical Experiment,” Digital Humanities Conference, 2017.
[44]See P. Caton, G. Ferraro and L. Figueira, et al., “Mechanizing the Humanities? King’s Digital Lab as Critical Experiment.”
[45]See D. Quinn and L. Joan, “A Capacity Building Framework for Institutional Digital Humanities Support.”
[46]参见柯平、宫平:《数字人文研究演化路径与热点领域分析》,《中国图书馆学报》2016年第 6期。
[47]See H. Green, E. Dickson and D. Tracy, et al., “Building a Bridge to Next Generation DH Services in Libraries with a Campus Needs Assessment”; A. Keener, “The Arrival Fallacy: Collaborative Research Relationships in the Digital Humanities.”
[48]参见“China Biographical Database”,网址为:https://projects.iq.harvard.edu/chinesecbdb.
[49]See I. Muiser, M. Theune and R. De Jong, et al., “Supporting the Exploration of Online Cultural Heritage Collections: The Case of the Dutch Folktale Database.”
[50]See U. Springmann and A. Lüdeling, “OCR of Historical Printings with an Application to Building Diachronic Corpora: A case Study Using the RIDGES Herbal Corpus.”
[51]See M. Kestemont and D. Stutzmann, “Script Identifi cation in Medieval Latin Manuscripts Using Convolutional Neural Networks,” Digital Humanities Conference, 2017.
[52]See S. A. Oliveira ,F. Kaplan and di Lenardo, “Machine Vision Algorithms on Cadaster Plans.”
[53]See T. Causer, K. Grint and A-M Sichani, et al., “‘Making Such Bargain’: Transcribe Bentham and the Quality and Cost-eff ectiveness of Crowdsourced Transcription,” Digital Scholarship in the Humanities, vol. 33, no. 3 (2018).
[54]See M-C Beaulieu, F. Baumgardt and B. Almas , “Perseids and Plokamos: Weaving Pedagogy, Data Models and Tools for Social Network Annotation,” Digital Humanities Conference, 2017, p. 161.
[55]See P. Francois,J. Manning and H. Whitehouse, et al., “A Macroscope for Global History Seshat global History Databank: a Methodological Overview.”
[56]参见“CBETA数位研究平台”,网址为:http://cbetaonline.cn.
[57]参见“DocuSky数位人文学术研究平台”。
[58]See A. Crymble, “Digital Library Search Preferences Amongst Historians and Genealogists: British History Online User Survey.”
[59]See I. Muiser,M. Theune and R. De Jong, et al., “Supporting the Exploration of Online Cultural Heritage Collections: The Case of the Dutch Folktale Database.”
[60]See R. Cordell and D. Smith, “What News is New: Ads, Extras, and Viral Texts on the Nineteenth-century Newspaper Page”; Cooney C and Gladstone C, “Tracing Swerves of Infl uence: Text Reuse and the Reception of Lucretius in 18th-century England”; G. Franzini and M. Büchler, “Orosius’ Histories: A Digital Intertextual Investigation into the First Christian History of Rome”; Romanello M, “Exploring Citation Networks to Study Intertextuality in Classics.”
[61]See Y. Bizzoni,M. Reboul and A. Del Grosso, “Diachronic Trends in Homeric Translations,” Digital Humanities Quarterly, vol. 11, no. 2 (2017).
[62]See D. Sturgeon, “Unsupervised Identifi cation of Text Reuse in Early Chinese Literature,” Digital Scholarship in the Humanities, vol. 33, no. 3 (2018).
[63]See E. Franzini and M. Büchler, “From Jane Austen’s Original Pride and Prejudice to a Graded Reader for L2 Learners: A Computational Study of the Processes of Text Simplifi cation,” Digital Humanities Conference, 2017;
E. Ketzan and C. Schöch , “What Changed When Andy Weir’s the Martian Got Edited?” Digital Humanities Conference, 2017; E. Beshero-Bondar and R. Viglianti, “Hierarchies Made to be Broken: The Case of the Frankenstein Bicentennial Variorum Edition,” Digital Humanities Conference, 2018.
[64]See M. Eisen,A. Ribeiro and S. Segarra, et al., “Stylometric Analysis of Early Modern Period English Plays,” Digital Scholarship in the Humanities, vol. 33, no. 3 (2018).
[65]See M. Eder, “Short Samples in Authorship Attribution: A New Approach,” Digital Humanities Conference, 2017.
[66]See J. C. Tello, D. Schlör and Henny, et al., “Neutralising the Authorial Signal in Delta by Penalization: Stylometric Clustering of Genre in Spanish Novels,” Digital Humanities Conference, 2017.
[67]参见K. Baierer,E. Dröge and K. Eckert, et al., “DM2E: A linked Data Source of Digitised Manuscripts for the Digital Humanities”; 夏翠娟、张磊:《关联数据在家谱数字人文服务中的应用》,《图书馆杂志》2016年第 10期。
[68]See R. Studer,V. R. Benjamins and D. Fensel, “Knowledge Engineering: Principles and Methods,” Knowledge Engineering, vol. 25, no. 1 (1998).
[69]See I. Kyvernitou and A. Bikakis, “An Ontology for Gendered Content Representation of Cultural Heritage Artefacts.”
[70]See F. Kräutli, M. Valleriani and E. Chen, et al., “Digital Modelling of Knowledge Innovations in Sacrobosco’s Sphere: A Practical Application of CIDOC-CRM and Linked Open Data with CorpusTracer,” Digital Humanities Conference, 2018.
[71]See B. Jussen, A. Mehler and A. Ernst, “A Corpus Management System for Historical Semantics,” International Journal for Language Data Processing, vol.31, no.1-2 (2007).
[72]See G. Prebor, M. Zhitomirsky-Geff et and O. Buchel, et al., “A new Methodology for Error Detection and Data Completion in a Large Historical Catalogue Based on an Event Ontology and Network Analysis,” Digital Humanities Conference, 2018.
[73]See Y. Lecun,Y. Bengio and G. Hinton, “Deep Learning,” Nature, vol. 521, no. 7553 (2015), p. 436.
[74]See S. A. Oliveira and F. Kaplan, “Comparing Human and Machine Performances in Transcribing 18th Century Handwritten Venetian Script”; S. M. Dashti, A. Khatibi Bardsiri and V. Khatibi Bardsiri, “Correcting Real-word Spelling Errors: A New Hybrid Approach”; S. Grieggs, B. Shen and H. Muller, et al., “Verba Volant, Scripta Manent: An Open Source Platform for Collecting Data to Train OCR Models for Manuscript Studies,” Digital Humanities Conference, 2018, pp. 386-390.
[75]See S. A. Oliveira and F. Kaplan, “Comparing Human and Machine Performances in Transcribing 18th Century Handwritten Venetian Script.”
[76]See S. M. Dashti,A. Khatibi Bardsiri and V. Khatibi Bardsir, “Correcting Real-word Spelling Errors: A New Hybrid Approach.”
[77]See S. Grieggs, B. Shen and H. Muller, et al., “Verba Volant, Scripta Manent: An Open Source Platform for Collecting Data to Train OCR Models for Manuscript Studies.”
[78]See K. Kettunen,E. Mäkelä and T. Ruokolainen, et al., “Old Content and Modern Tools-searching Named Entities in a Finnish OCRed Historical Newspaper Collection 1771-1910.”
[79]参见赵妍妍、秦兵、刘挺:《文本情感分析》,《软件学报》2010年第8期。
[80]See I. Leemans, V. D. J. M. van der Zwaan,I. Maks,et al., “Mining embodied emotions: A comparative analysis of sentiment and emotion in Dutch texts, 1600-1800.”
[81]See S. Buechel, U. Hahn and J. Goldenstein, et al., “Do Enterprises Have Emotions?” Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, 2016; S. Buechel, J. Hellrich and U. Hahn, “The Course of Emotion in Three Centuries of German Text—A Methodological Framework,” Digital Humanities Conference, 2017.
[82]参见谌志群、张国煊:《文本挖掘研究进展》,《模式识别与人工智能》2005年第1期。
[83]See R. Rehurek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora.”
[84]See Garcia-Zorita C. and Pacios A. R., “Topic Modelling Characterization of Mudejar Art Based on Document Titles.”
[85]See A. S. Garcia, “Interrogating the Roots of American Settler Colonialism: Experiments in Network Analysis and Text Mining,” Digital Humanities Conference, 2018.
[86]See C. Schöch, “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.”
[87]See S. Pielström, S. Simmler and T. Vitt, et al., “A Graphical User Interface for LDA Topic Modeling,” Digital Humanities Conference, 2018.
[88]See J. Armoza, “How to Close Read a Topic Model: TWiC Reads Emily Dickinson’s Fascicles,” Digital Humanities Conference, 2017.
[89]参见刘军:《社会网络分析导论》,北京:社会科学文献出版社,2004年。
[90]See C. Edmondson, “An Enlightenment Utopia: The Network of Sociability in Corinne.”
[91]See S. Jänicke and J. Focht, “Untangling the Social Network of Musicians.”
[92]See S. Mahony, “The Digital Classicist: Building a Digital Humanities Community.”
[93]See L. Evalyn,S. Gauch and M. Shukla , “Analyzing Social Networks of XML Plays: Exploring Shakespeare’s Genres.”
[94]See U. Hinrichs and S. Forlini, “In Defense of Sandcastles: Research Thinking through Visualization in DH.”
[95]See K. L. Ferguson, “Digital Surrealism: Visualizing Walt Disney Animation Studios,” Digital Humanities Quarterly, vol. 11, no. 1 (2017).
[96]See W. Jeong and H. Han, “Media Visualization of Book Cover Images: Exploring Diff erences among Bestsellers in Diff erent Countries.”
[97]See L. T. Tran, K. Park and P. Lee, et al., “Chromatic Structure and Family Resemblance in Large Art Collections—Exemplary Quantifi cation and Visualizations,” Digital Humanities Conference, 2018.
[98]See P. Murrieta-Flores,C. E. Donaldson and I. N. Gregory, “GIS and Literary history: Advancing Digital Humanities Research through the Spatial Analysis of Historical Travel Writing and Topographical Literature,” Digital Humanities Quarterly, 2017, vol. 11, no. 1 (2017).
[99]参见“CHGIS在线平台”,网址为:http://www.people.fas.harvard.edu/~chgis/.
[100]See J. A. Jenstad, T. Landels-Gruenewald and J. Takeda, “Mapping the STC with MoEML and DEEP,” Digital Humanities Conference, 2017.
[101]参见林富士:《数位人文学白皮书》。
原刊《数字人文》2020年第1期, 转载请联系授权。