您正在访问旧版存档页面。This is the old version archive of our site.

正则表达式在描述与分析古书文本通例中的应用——以《毛诗正义》篇题为例
古书中存在着大量的文本通例,它们对于阅读古书起着非常重要的作用,从古至今……
作者:李林芳;转自:公众号 DH数字人文
文本分析

李林芳 / 北京大学中文系
———————————————-
摘 要: 古书中存在着大量的文本通例,它们对于阅读古书起着非常重要的作用,从古至今一直备受关注。本文以《毛诗正义》的篇题为例,研究了正则表达式在描述和分析古书文本通例中的应用。相较于传统的描述形式(自然语言),正则表达式具有更强的优越性,包括准确、简洁、无歧义、易评价等;在归纳通例时方向明确、高效准确;还能成为传统研究的重要辅助;并能与计算机紧密结合,应用于更广泛的文本研究中。尤其在评价“通”性、展示归纳过程、处理大量材料等方面,传统通例很难解决相应问题,而正则表达式描述的通例则较易处理。正则表达式应更普遍地应用到对文本通例的撰写中去,成为协助描述和分析文本通例的主要工具;亦可考虑不使用自然语言,而直接以正则表达式的形式呈现文本通例。
关键词: 文本通例 正则表达式 《毛诗正义》 篇题注释
———————————————-
中国的古代文本中可见大量的通例。在清代,学者们已普遍有意识地对这些通例进行归纳总结,以有助于读懂古书。从自然语言处理的角度看,很多文本层面的通例(下简称“文本通例”)其实都是对具有某种共通模式的字符串的自然语言描述,故而可以转用正则表达式书写出来。通过使用正则表达式,再结合其他手段,我们可以对古代文本进行更深入的研究。本文即以《毛诗正义》的篇题为代表,探索正则表达式在描述和分析古书文本通例上的应用。
本文之所以选择《毛诗正义》的篇题作为例子,是由于这些文字呈现了很明显的规律性,其中必然蕴含着相应的文本通例。但前人对其关注不多,对其间规律尚未予以充分阐明。本文希望通过这一研究,一方面发掘《毛诗正义》篇题的撰写规律、揭示其中通例;另一方面展示以正则表达式来描述和分析古代文本通例的途径和方法,表明其所具有的优越性;最后说明以正则表达式描述的通例还能应用在古书相关研究的哪些方面,进一步思考其对于古代文本研究的意义。
一、《毛诗正义》的篇题
在《毛诗正义》中[1],每诗之后皆有篇题(从其位置看,也可以称为“尾题”)。其中除该诗的标题信息外,还含有诗的章句信息。如《周南·葛覃》:
《葛覃》三章,章六句。
此篇题即在《周南·葛覃》的最末,意为《葛覃》这首诗共有三章,每章含六句诗。
由于《葛覃》每章句数皆相等,只需用一句话说明每章所含句数即可,故此篇题表达较为简略。此外,又有更为复杂的篇题,如《召南·行露》:
《行露》三章,一章三句,二章章六句。
由于《行露》三章中第一章和第二、三章的句数不相同,故需分类说明。此篇题意为:《行露》一诗共三章,其中某章中有三句诗,另两章每章中有六句诗。此外,从篇题中我们还发现另一个特征:当含有同样句数的章数为“一”时,则只用一个“章”字,如例中的“一章三句”;当含有同样句数的章数目大于“一”时,则用两个“章”字,如例中的“二章章六句”。
又如《鄘风·君子偕老》:
《君子偕老》三章,一章七句,一章九句,一章八句。
与《行露》不同,《君子偕老》诗三章中每章句数皆不相同,故需分开来一一说明。此篇题意为:《君子偕老》一诗共三章,其中某一章有七句,某一章有九句,某一章有八句。
我们还注意到对于只有一章的诗,篇题表述略显特殊,如《周颂·清庙》:
《清庙》一章,八句。
与前面几例不同,由于该诗只有一章,所以篇题在描述其句数时直接略去了数字前的“章”字。此篇题意为:《清庙》这首诗一共只有一章,该章含八句诗。
此外,某些篇题末后又有“故言”的说法。如《周南·关雎》:
《关雎》五章,章四句。故言三章,一章章四句,二章章八句。
关于“故言”,《经典释文》进行了解释:“五章是郑所分,故言以下是毛公本意,后放此。”[2]也就是说,故言之前的部分是郑玄所分章句,故言之后是毛公《毛诗故训传》所分章句。由于郑玄在毛公之后又对《毛诗》重新划分章句、进行注解,所以我们今天见到的《毛诗》文本的章句并非毛公时的面貌,而是经郑玄改动后的结果。而毛公与郑玄章句不同者,就在部分篇题中以“故言”的形式保留了下来。
不过在《毛诗正义》全部305首诗中,含有“故言”的篇题仅3首,由于故言部分呈现章句信息的规律与非故言部分完全一致,且所涉篇题数量极少,又易于辨识;下文在讨论篇题时暂将“故言”部分的文字略去。
总之,通过对各诗篇题的分析,《毛诗正义》中的篇题除去“故言”例共计四类,它们包含了所有的篇题情况。下面我们将在此基础上,展开对篇题结构的讨论。
二、协助描述与归纳篇题结构的通例
从以上对篇题类型的呈现中,我们可以发现《毛诗正义》的篇题结构似乎有很强的规律性,其中应能归纳出相应通例。从最显而易见的层面上,可以发现所有篇题皆由“诗名+章信息+句信息”构成。故而可以用以下正则表达式匹配:
^《.+》.+章.+句。$ (式A)
虽然就表面上看,式A已可不多不少地覆盖《毛诗》文本中的全部篇题。但是其写法过于笼统,无法具体反映《毛诗正义》四类篇题的特性,也无法据之对篇题本身展开研究。此外,该式还有较为严重的问题,即其所匹配的某则篇题经进一步分析可知非属真正的《毛诗正义》的篇题,关于这一点我们将在第三节中予以阐述。鉴于此,我们将进一步分析篇题的特征,以求获得更为精准的描述。
从上节所举例中,我们发现《毛诗正义》的篇题结构具有下述特点:
- 1.整体为诗名+章信息+句信息的格式。
- 2.章信息的格式为章数目+章。
- 3.句信息又能分为以下三种情况:
- a.章数目为1,则句信息的格式为句数目+句。
- b.章数目大于1,又有以下两种情况:
- i.若含有同样句数的章数目等于1,则句信息的格式为一+章+句数目+句。
- ii.若含有同样句数的章数目大于1,则句信息的格式为含有同样句数的章数目+章章+句数目+句。
- 4.章信息只出现一次,句信息可重复出现。
- 5.以上所有的章数目和句数目皆为中文数字。
- 6.所有诗名皆加书名号标点,章信息与诗名之间没有标点;章信息之后为逗号;非最末的句信息之后为逗号,最末的句信息之后为句号[3]。
以上只是对《毛诗正义》篇题通例的自然语言描述,下面列出由其转写成的正则表达式(式B)。为方便阅读,我们在此使用了宽松排列的表达式(free-form expressions),并在必要的行后加了注。这些正则表达式皆在Python3.6.0平台,使用re包,修饰符(modifier)设为re. MULTILINE| re. VERBOSE的状态下运行通过。

式B的匹配情况如下:
表1 式B的精确率与召回率
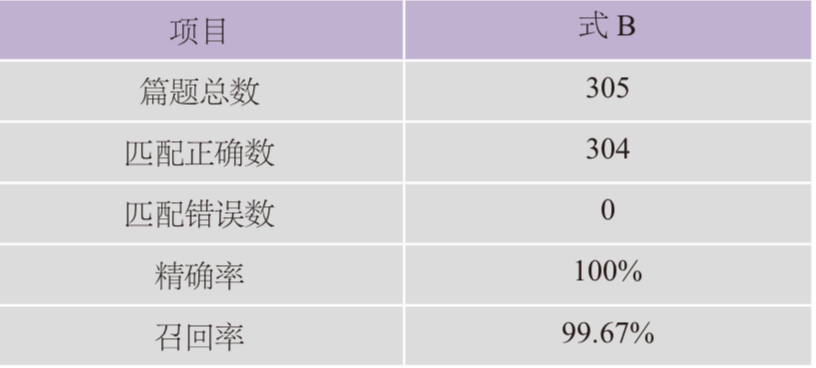
该式可以匹配305首诗的304首篇题。至于一首诗的篇题为何没能成功匹配,其实是文本讹误所致,并非该表达式本身有问题。具体情况我们将在下节予以说明。
根据该匹配结果,我们可以确信地知道,式B对于《毛诗正义》篇题的描述是非常准确的;也就是说,该正则表达式可以作为《毛诗正义》篇题结构形式化的精准描述:在《毛诗正义》文本中,能被该表达式匹配的字符串,就应该是《毛诗正义》的诗篇篇题;不能被该表达式匹配的字符串,就应该不是《毛诗正义》的诗篇篇题。
关于《毛诗正义》的篇题通例,清人亦曾用自然语言予以描述,为:“‘一章’下例不重‘章’字。”[4]对应于上文所述的第3.b.i项特点。与之相比,使用正则表达式描述古代文本通例的优越性便昭然可见。首先就是描述的准确性。如同清人所指出的通例一般,过去对于通例的描述往往只是用言语叙说被描述对象的概貌或某一方面的突出特征,难免略显主观;而采用正则表达式进行描写就可囊括全面的情况:从细节至总貌无不涵盖在内,如此则更为客观。其次是描述的简洁性。若要达到同样或相近的准确程度,自然语言明显用字更多,显得繁复啰嗦;而正则表达式则用字较少,更为简洁紧凑。如本条篇题通例,自然语言表述的文字共计273字符,式B则只有124字符[5]。再次,由于自然语言本身的特性,再详尽的描述也难免造成歧义。如在清人的这则描述中,“一章”到底指的是篇题结构中的哪处或哪几处文字,较不明确,需得仔细查核一番方知。与之不同,使用正则表达式这样形式化的表述,就完全消除了歧义:针对特定的正则表达式,某一字符串只有合或不合两种情况,不存在模棱两可、依违之间的情形。第四,由于自然语言存在模糊空间,以及手工检测效率低下,使用自然语言来描述的通例不易使人知晓其“通”到底能通多少,也就是说不易检核某通例跟该通例用以描述的对象之间多少相符,多少不符,以及是否还有多收的情形,从而难以对通例的准确性做出评价。就像“例不重‘章’字”的说法,仅凭这段文字,我们无从知晓这一“例”到底普遍到什么样的程度:是少半如此,多半如此,还是全部如此?与之不同,使用正则表达式来描述通例,借助计算机检索,我们很容易知晓该正则表达式与目标文本的匹配状况——精确率是多少、召回率是多少,基于此就能对通例的“通”性做出衡量,从而评判并明了哪一通例“更优”。
正则表达式易于判断“更优”的这一特性,还能有助于我们归纳通例。就传统情况而言,由于缺少衡量与评价标准,在做归纳时难以判断起始点、归纳方向与结束条件,似乎觉得“差不多”就可以了,不易给出明晰的步骤。而使用正则表达式,归纳通例的过程就可以明确安排如下:
- 1.随机挑选部分目标文本,书写与之匹配的正则表达式。
- 2.用已写好的正则表达式匹配全文,检查精确率与召回率。
- 3.根据以上情况调整正则表达式。
- 4.重复2、3步骤,直到精确率和召回率都维持在较高的程度且不再变化为止。
- 5.该正则表达式即为目标文本的通例。对应的精确率和召回率即可作为对该通例准确性进行评价的指标。
其实,我们对《毛诗正义》篇题通例的归纳也是依循以上步骤进行的,共分为四步(正则表达式中加粗的部分为对前一步骤式子的修改之处):
表2《毛诗正义》篇题通例的归纳步骤
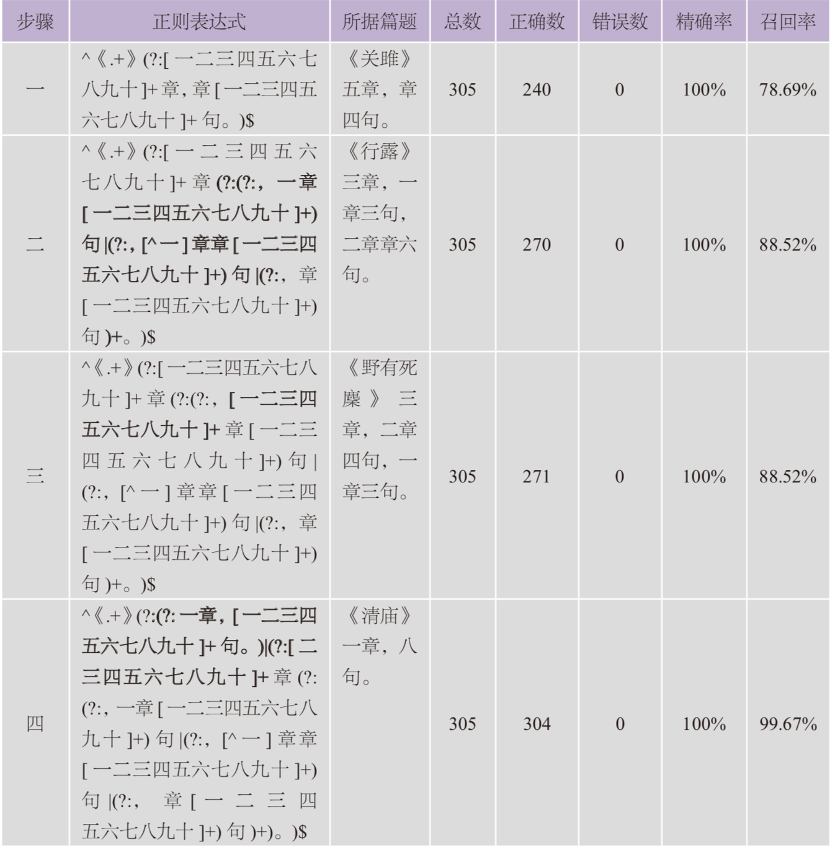
在归纳篇题通例时,我们首先据第一首诗《关雎》的篇题撰写正则表达式,发现共能匹配240首篇题,精确率为100%,召回率为78.69%。其次,我们从步骤一中第一首不能匹配的诗题开始,为《行露》,据之修改原正则表达式;修改后的表达式共能匹配270首篇题,精确率不变,召回率增加了10%。再次,我们从步骤二中第一首不能匹配的诗题开始,为《野有死麇》,据之修改原正则表达式;修改后的表达式共能匹配271首篇题,仅新匹配了一首,召回率几乎没有增加;同时,我们又发现《野有死麇》的篇题在文本上有问题,故该式不予保留。最后,我们从步骤二中第二首不能匹配的诗题开始,为《清庙》,据之修改原正则表达式;修改后的表达式共能匹配304首篇题,精确率不变,召回率增加了11%。此时,除《野有死麇》一首诗外,其余诗的篇题皆可正确匹配,故步骤四的正则表达式即可作为《毛诗正义》篇题的形式化描述,至此对《毛诗正义》篇题通例的归纳过程便可宣告结束。
我们认为,这一归纳通例的方法相较于传统方法具有以下优点:首先,有更明确的判断和修改标准。由于可以很方便地计算精确率和召回率以判断是否有多收或漏收现象,故而能方向明确、具有针对性地修改正则表达式。其次,这也意味着效率能得到保障。因为有了明确的标准,起始点、修改方向、结束点都能清楚地判断出来,从而能避免来回反复的情形发生,所以能提高效率。再次,准确性更高。由于可以精确率、召回率为依据进行量化评价,从而能有效避免因遗漏而调整通例后,带来新的多收现象;或因多收而调整通例后,带来新的遗漏现象:故此最后得到的通例能保持更高的准确性。最后,归纳过程能得到具体呈现。前人在陈述某条通例时,一般只说明所得结果,罕见对归纳过程的详细记录。似乎归纳者通过阅读目标文本,一下子就总结出了其中规律,并进而形诸文字成为通例。但是该例到底是如何一步步总结出来的,其过程演于脑中,存在灵感直觉的成分,难以直接展现;他人即便想查核和改良也无从下手,只能另起炉灶。如今通过正则表达式,有理有据,也方便他人覆案验核,乃至更易改进。
总之,相较于使用自然语言描述文本通例,使用正则表达式描述通例有更大的优越性。这一优越性不仅体现在最后呈现的通例结果之上,还体现在寻找通例的过程之中。
三、协助校勘文本
前文已述,若正则表达式所描述的通例能覆盖几乎所有的情况,却有极少数的例外,那么这些例外很有可能是由于文本讹误所致,而非通例本身的问题。如此一来,正则表达式也可以作为“理校”的有力手段应用到校勘之中,成为协助校勘文本的重要方法。
前文已多次述及,就我们对《毛诗正义》各诗篇题结构的归纳而言,可以发现其通例尚有一条不能涵盖的情形,为《召南·野有死麇》的篇题:
《野有死麇》三章,二章四句,一章三句。
从本文第一节所举例和我们对于通例的描述和书写中,可知对于篇题而言,若含相同句数的章数等于一,则表述为“一章多少句”,其中只有一个“章”字;然而若含相同句数的章数大于一,则表述为“多少章章多少句”,其中有两个章字。此篇题中却出现了例外:含相同句数的章数为二,却表述为“二章四句”,未再重复“章”字。由于已用正则表达式匹配过《毛诗》的全部文本,只有这一处篇题不能被匹配;所以我们知道,对于除此例之外的其他篇题,以上的观察都是成立的,仅在此例中没有成立。因此我们有充分的理由怀疑此篇题的文本可能有问题,即“二章”的“章”下遗漏了一个“章”字,原文应作“二章章四句”。
以上仅是从规律的角度进行的推论而已。具体是否如此,还需要有真实的版本证据才能敲定。查考宋巾箱本[6]和监本[7]《毛诗》,可见其中皆作“二章章四句”,重一“章”字。由此可证,我们所据的南昌府学本《毛诗正义》此处篇题应有讹误;其中“二章四句”应作“二章章四句”,某“章”字可能因涉另一“章”字而致讹脱。清人在校勘《毛诗正义》时于此处未指出其误,我们的这一考察正可作为补充。
另外有意思的是,监本《野有死麇》篇题亦有一误。其原文作:“《野有死麇》三章,二章章四句,一章章三句。”根据我们上面的讨论和其他版本证据,可知这里正确的表述应是“一章三句”。《野有死麇》篇题“一章章三句”可能涉前文“二章章四句”而衍一“章”字。由此可见,篇题中此类或增或缺的讹误还是比较常见的。
清人对这一现象也有所注意。我们于第二节中曾提及清人对篇题通例的描述:“‘一章’下例不重‘章’字。”该句为《周南·关雎》篇题“《关雎》五章,章四句。故言三章,一章章四句,二章章八句”的校勘记,其全文作:“案,‘一章’下例不重‘章’字,次‘章’字误衍。”[8]这段校记正指出了前述规律,但并未详释原因。今按,有“章”字和无“章”字并非随意而为,而是有语义上的基础的。所谓“二章章四句”,指的是“两章诗中的每章有四句诗”,第二个“章”表示的是“每章”的意思。而“一章三句”,指的是“一章诗中有三句诗”;由于所描述的对象仅止“一章”,这时再说“每章”就很奇怪了。同理,前文也提到,对于只有一章的诗,之后再说句信息时只需要说“多少句”即可,不再需要“章”字;因为其中只有一章,这时再加“章”字表示“每章”之义也就说不通了。明白“章”字的用法,对于校勘《诗经》及其他古籍中的类似文本都将会有很大的助益。
总而言之,由于正则表达式具有非常方便的匹配文本的功能且无歧义,所以据之我们能很容易地发现以之写成的通例有多少“例外”的状况,而这些例外正暗示着可能的文本讹误。同时,由于正则表达式本身就意味着一类文本的模式,包含着清楚的规律性的信息,所以可以作为校勘时的“理校”材料。在辅助文本校勘方面,正则表达式有着极大的潜力,还有待我们进一步的发掘。
还有一点值得说明的是,上节提到式A可以匹配全部305首诗题,式B只能匹配304首诗题。但是通过本节的分析可知,式A所匹配的305首诗题中,《野有死麇》的诗题并非“正确的”《毛诗正义》的诗题。如此,式A与式B的精确率与召回率如下表所示:
表3 式A式B精确率与召回率之比较
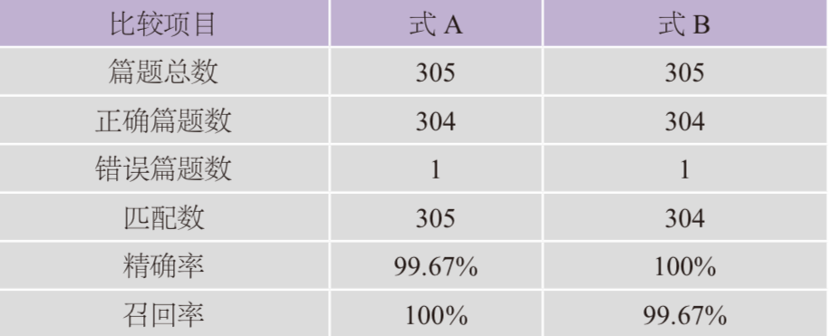
从表中可见,式A的精确率是99.67%,召回率是100%;式B的精确率是100%,召回率只有99.67%。二者相较,显然式A的鲁棒性强,但对于通例研究而言,不易发现例外。考虑到古代文本的特殊性质——其中常见文本讹误,故此我们建议在撰写通例所对应的正则表达式时尽量写得更加细致一些,这样有助于提高精确率,有利于讹误的发现与校勘的开展。
四、辅助其他相关研究
此外,由于正则表达式具有非常便利的提取文本的功能,所以还能为许多研究提供辅助。例如对于篇题,还存在另一个问题:《毛诗正义》篇题中对有共同句数的章的表达进行了归并——如上述《野有死麇》“二章章四句”,而不会说成“一章四句,一章四句”这么繁琐——那么归并之后,各个句信息的顺序是依照什么样的原则来排列的呢?其中有一定的规律,还是没有规律?
这一问题可能涉及面较小,研究起来又比较烦琐,前人还没有专门讨论过,但对于彻底弄清篇题的编写方式并指导我们今天撰写类似篇题还是具有意义的。从常理推测,其中应有一定规律,而且依循的应该是“向前归并”的原则。也就是说,当第一次出现某一句数不同的章时,该句数在最后的篇题中的位置即已固定下来了;之后再出现与之相同句数的章时,哪怕又隔了几个句数不同的章,该章依然会被归并到之前该句数信息第一次出现的位置上去(而非不归并),且该句数信息的位置也不发生变化。
在此举两个例子。比如《鲁颂·閟宫》这首诗,共八章,每章所含句数依次排列如下:17,12,38,17,8,8,10,10。可以注意到,其中虽然有两章皆为17句,可它们中间又间隔了含有不同句数的章,那么其篇题应如何描述?如果我们推测的归并方法与实际相符,则第四章的17句应与第一章的17句合并起来在篇题中进行说明,且排在篇题句信息的第一位;其他句数则依次向后排列。如此,其篇题或可如下描述:“《閟宫》八章,二章章十七句,一章十二句,一章三十八句,二章章八句,二章章十句。”今检《閟宫》尾题,其描述与我们的推测完全相符。又如《商颂·殷武》一诗,共六章,每章句数排列如下:6,7,5,6,6,7。根据我们的推测,第四章、第五章应与第一章合并起来说明,第六章应与第二章合并起来说明,则应做如下描述:“《殷武》六章,三章章六句,二章章七句,一章五句。”今检《殷武》尾题,其描述亦与我们的推测相一致。由此可见,我们所提出的“向前归并”的原则应是有很大的可能性的。
不过若想完全证实这一推测,则需要对全部的篇题进行验证。按照传统做法,需数出每首诗的章数,每章的句数,按照我们的推测给出篇题可能的描述,再与该诗实际的篇题进行核对。可这么一来,要对305首诗一一统计,不仅非常费时费力,还极易出错。所幸现在有计算机的便利,我们只要写一程序,即可轻松进行验证。该程序的构思非常简单:数出一首诗有多少章,每一章有多少句,据此生成该诗的可能篇题;然后由正则表达式直接提取该诗的真实篇题,与可能篇题核对;最终输出全部的比较结果,并将不合的结果标上记号。由于《诗经》文本本身即具有较显明的格式,而且我们又对手上的《毛诗》文本进行了一些简单的清理和统一工作,所以很容易处理每诗的信息。
这是处理后的《毛诗》中各诗的文本结构:
诗序号《诗题》
第1章第1句,第1章第2句,…,第1章第x句。
第2章第1句,第2章第2句,…,第2章第y句。
…
第n章第1句,第n章第2句,…,第n章第z句。
篇题
经过程序检测,我们发现除含“故言”的3例和有讹误的《野有死麇》1例外,在余下301首诗中仅有一处可能篇题与真实篇题不符。这一例为《鄘风·载驰》,其篇题作:
《载驰》五章,一章六句,二章章四句,一章六句,一章八句。
《载驰》一诗共有五章,其每章所含句数依次为6,4,4,6,8。根据我们的推测,其篇题应写作“二章章六句,二章章四句,一章八句”,即将有共同句数的第一章与第四章相合并,第二章与第三章相合并。但是实际情况却与推测的情形不一致,实际只将第二章与第三章合并,却未将第一章与第四章合并。我们认为,这应是编写篇题者的偶疏。因为对于其他类似情况的诗,如我们前文所举的《鲁颂·閟宫》《商颂·殷武》,其未相邻的含有相同句数的章皆被归并了,仅有此处例外。或有可能是不同学派的不同文本所导致的,如汉代别家《诗经》文本对篇题的写法与《毛诗》不一致,《毛诗》此处将别家文本掺入在内,从而导致了这一情形。但由于并无文本证据,故此仅为猜测,无法证实。
无论如何,根据以上的检测结果,我们可以知道之前的推断是靠得住的。也就是说,对于篇题的撰写,撰写者严格遵循了我们之前所描述的“向前归并”的原则——仅有一处可能因疏失或文本问题造成的例外。在这一研究中,正则表达式主要起到了提取《毛诗》原文篇题信息的作用。通过提取文本以便计算机自行比对,不仅节省了大量时间,还避免了手工操作难以彻底规避的失误,可谓一举两得。
五、《毛诗正义》注释文本的通例与正则表达式
其实许多古代文本都有很强的规则性,从中可以总结出许多通例,并写出相应的正则表达式。就《毛诗》本身而言,除上述的篇题通例外,其注释文本也有着很强的规律性,并能总结为通例。如《毛传》和《郑笺》文本都有着明显的形式上的规律:这两个文本都位于双行小注中,且《郑笺》以“笺云”领起,如《周南·关雎》第二章“寤寐求之”的毛郑注释作:“寤,觉。寐,寝也。笺云:言后妃觉寐则常求此贤女,欲与之共己职也。”所以,《毛传》文本一般描述为:双行注释中“笺云”之前的文字(若无“笺云”,则是双行注释本身)。《郑笺》文本一般描述为:双行注释中“笺云”之后的文字。在我们的《毛诗》文本中,《毛传》和《郑笺》作为注释内容都以括号括上,以示在原文中为双行小字,并置于被注释的句子之后。据此,《毛传》的文本通例可以正则表达式书写为:
([^()箋 ]+(式C)
《郑笺》的文本通例可以正则表达式书写为:
箋云:[^)]+) (式D)
不过,若与《毛诗》中实际的传笺数相对,这两则式子的精确率与召回率都有问题,如下表所示:
表4 式C与式D的精确率和召回率
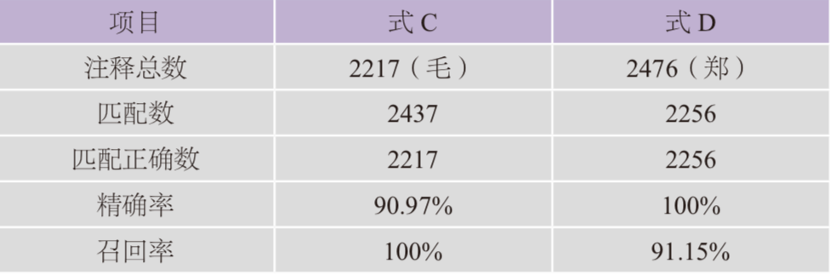
从表中可见,式C的召回率是100%,但精确率刚过90%;式D的精确率为100%,但召回率也不过才到91%。究其原因,是因为毛公未对诗序作注,只有郑玄之笺;于是诗序中的郑玄注释皆未以“笺云”领起,与诗句中的郑玄注释不同。所以在统计《毛传》数目时,需要将诗序中的相关注释排除;而在统计《郑笺》数目时,则要将诗序中的相关注释加上。由于诗序皆以诗名起始,故书名号可以作为诗序的标记。据此,《毛传》通例可以表述为:除诗序内容外,双行注释中“笺云”之前的文字(若无“笺云”,则是双行注释本身);其正则表达式可以修改为:
(?<!^《.*)([^()箋 ]+ (式E)
《郑笺》的通例可以表述为:双行注释中“笺云”之后的文字,和诗序双行注释中的文字;其正则表达式可以修改为:
箋云:[^)]+)|(?<=^《.*)([^()]+) (式F)
这两式皆在Python3.6.0平台,使用regex包,修饰符(modifier)设为regex. MULTILINE的状态下运行通过。它们的匹配情况如下表所示:
表5 式E与式F的精确率和召回率
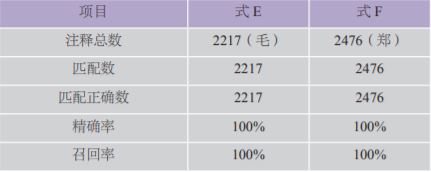
这样一来,两式的精确率和召回率都能达到100%。并且,从前后式匹配数的差额中,我们还能知道,诗序中含有的注释数为220条。不过这两式还有个小缺陷,由于它们涉及不定长的(non-fixed width)逆序环视,所以运用的范围较式C与式D都更为局限,如在python中需使用专门的regex包方能处理。
借助这两则表达式,首先,我们对《毛诗正义》中毛、郑的注释条目数做出了基本的统计[9]。在前人研究中,由于毛郑二家注释量太大,尚未见清楚完整的计数。如今利用正则表达式,我们可以清晰地知道在《毛诗正义》中,《毛传》注释了多少条,《郑笺》注释了多少条;对于两家的注释规模,终于有了明确的认识。其次,这些表达式也为计算机离析《毛诗正义》文本提供了便利。通过编写计算机程序进行匹配和提取,我们能有效地拆开《毛诗正义》的各个组成部分,逐一进行有针对性的分析,从而有助于文本研究、注释研究和其他相关研究的开展。
结 论
总结上文讨论,我们认为相较于传统的自然语言,使用正则表达式描述文本通例具有很强的优越性。这一优越性首先体现在对于文本通例的呈现上面,包括更准确而简洁的描述,完全消除歧义,易于对通例做出评价等;其次体现在归纳总结文本通例的过程方面,在归纳通例时方向明确、高效而准确;再次体现在辅助传统研究方面,如作为理校的依据协助校勘——其中尚有极大的潜力有待发掘;最后体现在与其他现代手段相结合上面,有利于在计算机的帮助下对文本进行迅速、准确的分析、统计与处理。特别地,确定一则通例到底能“通”多少、展示归纳通例的过程、将通例与(大量)文本相结合开展研究,这些问题以传统形式呈现的通例一般不容易应对,而以正则表达式书写的通例则能较为轻松地解决。
基于正则表达式自身的特性和强大的功能,我们建议:正则表达式应该更普遍地应用到对文本通例的撰写之中,成为协助描述和分析文本通例的主要工具;甚至可考虑在某些情境下不再使用自然语言,而直接以正则表达式的形式呈现文本通例。鉴于正则表达式无歧义、易检测的特性,我们进一步认为:只有能用正则表达式准确表达、并经精确率与召回率检验俱佳的文本通例,才是合格的文本通例。
(小文草成后,曾获美国印第安纳大学语言学系博士生胡海先生提供意见,投稿后又蒙评审专家多所指教。于兹并致谢忱!)
—————————————————————————————————————————————————————————
The Application of Regular Expressions to Describe and Analyze Textual Patterns in Ancient Chinese Texts:A Case Study of the Poem Titles in Maoshi Zhengyi
Li Linfang
Abstract: Textual patterns play an important role in revealing the meaning of ancient Chinese texts, and have been a great concern for scholars from ancient time till today. Normally, they are described by means of human’s natural language. However, regular expressions, which have been widely used in defining search patterns, could also be used to describe textual patterns. This paper explores the application of regular expressions tothe description and analysis of textual patterns of poem titles in Maoshi Zhengyi, and argues that, compared to natural language, regular expressions have the following advantages:(1) they present textual patterns in an exhaustive, concise and unambiguous way. (2)They do a great help in finding patterns in ancient Chinese texts, and make possible evaluation of a certain pattern. (3) They facilitate making textual criticism and other textual studies. (4) They pave way for processing ancient Chinese texts by means of computer programs. What’s more, there are several situations where textual patterns in the form of human’s natural language do not work, while those in the form of regular expressions work well. This paper finally suggests that regular expressions should serve as a main tool in describing and analyzing textual patterns in ancient Chinese texts, or even become the main form to present textual patterns in ancient Chinese texts.
Keywords: Textual Pattern; Regular Expression; Maoshi Zhengyi; Title Notes
—————————————————————————————————————————————————————————
编 辑 | 赵薇
注释:
[1]本文所用文本依据《毛诗正义》,台北:艺文印书馆,2007年影印本。原文无句读,本文标点依据为十三经注疏整理委员会整理:《毛诗正义》,北京:北京大学出版社,2000年。本文的《毛诗》文本含标题、诗序、经文、《毛传》《郑笺》这五项内容,不含《经典释文》和《正义》。另还有以下细节需要说明:1.标题分为首题和尾题。首题为我们所加,格式为“诗序号+诗名”,尾题为《毛诗正义》文本原有。2.在分段上,除传笺外,标题、诗序、每章经文皆单列为一行。3.传笺内容以圆括号括住,紧随在被注释的诗句之后。4.对于明显的标点错误,直接予以订正。5.所有文字皆为繁体汉字,以与底本相符。6.如下文所述,为了突出所要研究的问题,本文在讨论篇题时暂将“故言”部分略去,所以匹配时也会预先去除篇题中“故言”部分的文字(涉及3首)。如《周南·樛木》诗文本为:
《樛木》,后妃逮下也。言能逮下,而無嫉妬之心焉。(后妃能和諧衆妾,不嫉妬其容貌,恒以善言逮下而安之。)
南有樛木,葛藟纍之。(興也。南,南土也。木下曲曰樛。南土之葛藟茂盛。箋云:木枝以下垂之故,故葛也藟也得累而蔓之,而上下俱盛。興者,喻后妃能以意下逮衆妾,使得其次序,則衆妾上附事之,而礼義亦俱盛。南土謂荊、楊之域。)樂只君子,福履綏之!(履,祿。綏,安也。箋云:妃妾以礼義相與和,又能以礼樂樂其君子,使爲福祿所安。)
南有樛木,葛藟荒之。樂只君子,福履將之!(荒,奄。將,大也。箋云:此章申殷勤之意。將,猶扶助也。)
南有樛木,葛藟縈之。樂只君子,福履成之!(縈,旋也。成,就也。)《樛木》三章,章四句。
[2]陆德明著,黄焯汇校:《经典释文汇校》,北京:中华书局,2006年,第121页。
[3]篇题所据标点来源见前节脚注。
[4]《毛诗正义》,台北:艺文印书馆,2007年影印本。
[5]两段文字的空白字符、注释内容皆不计算在字符数内;前段文字的项目编号(“1.”等)计算在内。
[6]毛苌传,郑玄笺,陆德明释文:《毛诗诂训传》,北京:北京图书馆出版社,2003年影印本(中华再造善本),第22页。
[7]毛苌传,郑玄笺,陆德明释文:《监本纂图重言重意互注点校毛诗》,北京:北京图书馆出版社,2003年影印本(中华再造善本),第31页。
[8]《毛诗正义》,台北:艺文印书馆,第30页。此为“故言”之中的问题;由于“故言”所涉条目极少(3条)且易于辨识,为方便论述起见,本文暂将此部分文字略去,故前文说明篇题匹配情况时未涉及该例。
[9]需注意的是,这些注释条目数并非《毛传》与《郑笺》的训释总数,因为每条注释中可能包含多条训释和串讲。
原刊《数字人文》2020第2期,转载请联系授权。