您正在访问旧版存档页面。This is the old version archive of our site.

一种基于Transformer模型的古籍自动标点技术
人工加注古籍文献标点符号,即对无标点符号的古籍文献进行现代标点符号填充。但古籍数……
作者: 洪涛 程瑞雪 刘思汐 方凯齐 ;转自:公号 DH数字人文
文本分析

洪涛 / 古联(北京)数字传媒科技有限公司
程瑞雪 / 古联(北京)数字传媒科技有限公司
刘思汐 / 古联(北京)数字传媒科技有限公司
方凯齐 / 彩彻区明科技有限公司
————————————
摘要:人工加注古籍文献标点符号,即对无标点符号的古籍文献进行现代标点符号填充。但古籍数量庞大,人工加注费时费力。随着人工智能(AI)的兴起,基于深度学习实现自动标点工作可以减轻人工的繁重负担。本方法使用基于多头注意力机制的端到端Transformer模型作为训练模型,使用正规出版的10亿字古籍语料进行训练。模型在验证集上的标点F1为86.5%,断句F1为95.1%。随后在未训练的语料中抽取19本书作为测试集,结果显示,模型对古典文言文语料预测结果较好;对专业性较强和白话文占比较多的语料则效度较低。
关键词:古籍 自然语言处理 自动标点 机器学习 深度学习
————————————
一、概述
(一)相关研究
标点符号是当今人们理解文献作品的重要工具,然而很多古籍文献原本并没有标点符号,这就可能会使读者在阅读过程中无法理解古籍文献的真正涵义。自动标点,是指利用人工智能,根据特定算法自动给没有标点的古籍文本标注现代中文标点的技术。无需人工干涉,模型将通过学习所提供的“已经标点,且质量较高的古籍文本”[1]中的句子特点,自主选择特征值,结合现代标点用法实现对无标点古籍的标注。
早期黄建年等[2]根据李铎博士等提出的让计算机自学习进行古籍自动标点的构想[3]结合规则为主、计算为辅的方法,实现对农业古籍的断句。张开旭等[4]通过人工干涉特征值,使用条件随机场(conditional random field, CRF)[5]对古籍断句及标点进行建模。
后期随着深度学习的发展,神经网络模型被应用于自然语言处理的任务中。Huang[6]使用一种基于双向循环神经网络(bi-directional recurrent neural network)[7]添加CRF层的模型来解决序列标注的问题。俞敬松等[8]基于BERT(Bidirectional Encoder Representations from Transformers)[9]模型进行微调,从而实现对古文进行自动断句及自动标点的任务。
本文提出一种基于多头注意力机制的Transformer[10]模型,实现古籍自动标点和自动断句的目标。该方法通过在大量已出版的古籍数字版语料中自主学习语料特征,在随机选择的测试集中,比作为基准模型的LSTM模型和作为对比模型的BERT+CNN(Convolutional Neural Network,卷积神经网络)[11]模型展示出了更为优秀的表现。
(二)概念术语
标点是用来表示语句的停顿、语气以及标示某些成分(主要是词语)的特定性质和作用的。现代标点分为点号和标号两个种类。点号的作用是点断,主要表示停顿和语气,常用的有句号(。)、问号(?)、叹号(!)、逗号(,)、顿号(、)、分号(;)、冒号(:);标号的作用在于标明,主要标明语句的性质和作用,常用的有引号(“”)、括号(())、破折号(——)、省略号(……)、书名号(《》)等共9种。[12]本文所提到的标点符号仅限于点号。
二、方法与模型
(一)方法
我们将点号标注的任务看作是一种序列预测问题。即输入一段长度为n字的古文——一个s1,s2,……,sn的文本序列,模型将输出一个等长的T1,T2,……,Tn的标签序列,其中Ti代表原文中第i个汉字后所跟的点号。如果一个汉字后没有点号,我们则统一用一个代表不断句的符号“C”表示。
图1为本文所使用端到端模型搭配例句“三人行,必有我师焉。”的简要说明:该句中,“行”字和“焉”字后面对应的点号是“,”和“。”,其他字后不存在点号,因此原文s1,s2,……,s8“三人行必有我师焉”所对应的点号序列T1,T2,……,T8则为“CC,CCCC。”。我们将用不同的模型结构来学习预测这一序列。
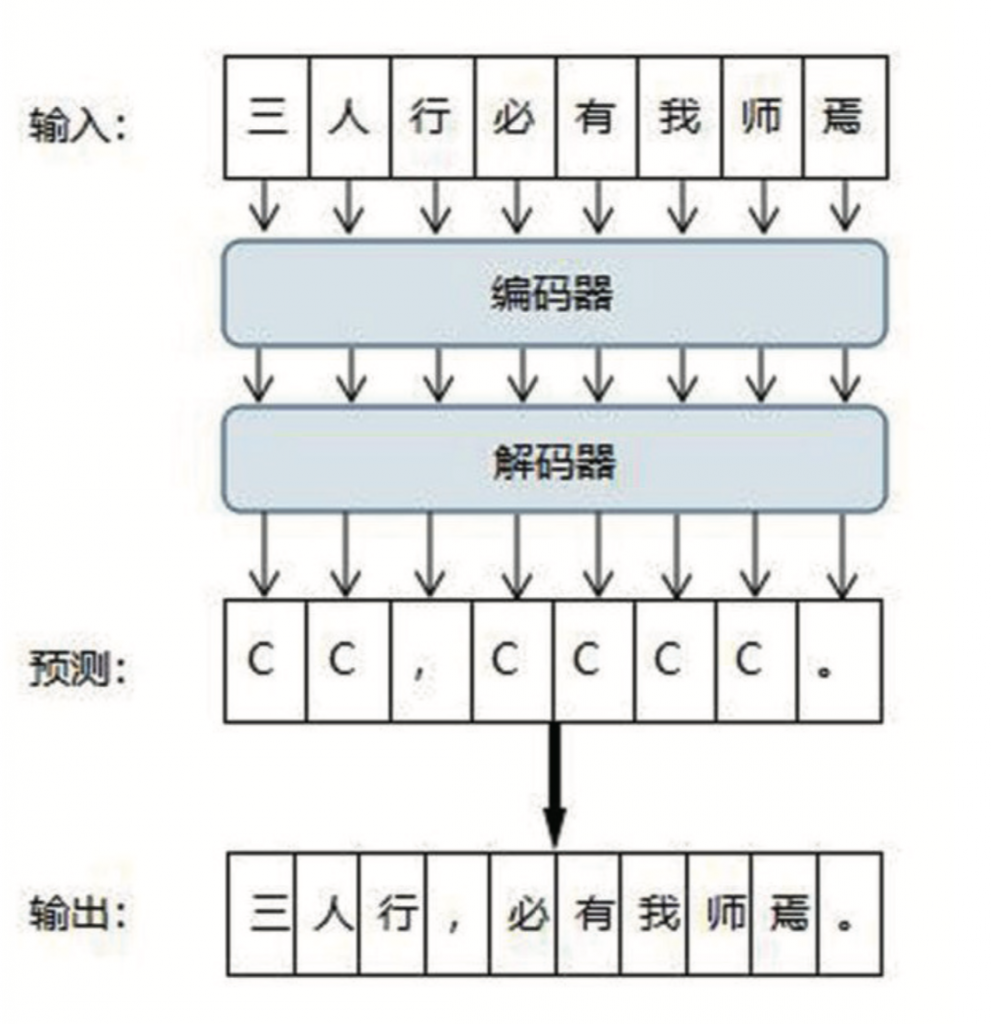
本文使用的Transformer模型采用自然语言处理中常用的端到端编码—解码[13]模型进行点号标注任务。该模型首先将输入汉字转化为对应的隐状态编码(Input Embedding),通过添加位置编码(Positional Encoding)得到一个带有输入文本中每个字完整信息的向量化表示。隐状态通过编码器(Encoder)后经过多层计算转化为高维度向量,并将结果输入到解码器(Decoder)中。解码器将输入结果进行进一步处理,然后通过线性(Linear)层将解码器输出的高维向量映射为以标点数量为维度的低维向量。最后,通过分类器层进行Softmax计算得到对应位置的标点结果预测概率。
(二)模型原理
在上节方法概述中所介绍的端到端编码—解码模型中的编码器的具体实现方法可以是多种的,比如编码器由Transformer模块构成,解码器由LSTM模块构成。BERT模型只需要Transformer模块组成的编码器加上分类器构成,不需要解码器。而本文中所提到的LSTM模型也仅是由LSTM模块编码器加分类器组合而成。具体的模块介绍如下。
1.Transformer模块
Transformer模型是自2017年出现以来,在多领域得到广泛使用的一类神经网络模块。模型的编码器部分每一层由一个多头注意力模块(Multi-Head Attention)和一个前馈层(Feed Forward)组成,其中的多头注意力模块由多个注意力(Attention)组成,单个注意力的公式为:
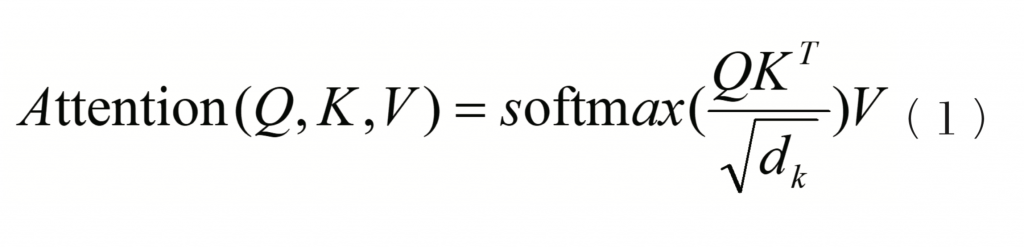
其中,Q为查询矩阵(query),K为键矩阵(key),V为值矩阵(value),由模型该层的输入通过独立的线性变换生成。dk为Q、K的向量维度,为计算方法中的缩放(scale)部分,该操作存在是为了让softmax的结果更为明显。
模型结构中使用的多头注意力则是通过线性变换得到设定好的注意力头数(h)份Q、K、V,各自进行注意力计算后,将参数不共享的不同注意力结果拼接起来,其公式为:
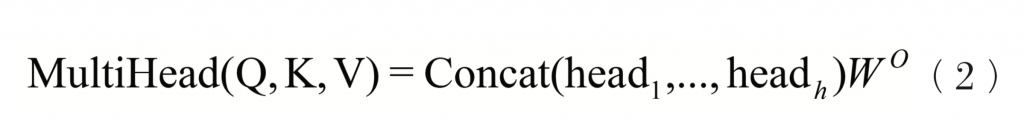
拼接好的多头注意力层的结果再通过残差连接和层归一化(Add & LayerNorm),以及前馈层,也就是一个全连接层和一个Relu激活函数后,完成一层Transformer层的计算。
解码器的每一层比编码器每一层多出一个多头注意力模块,其他组成基本一致。新增的注意力模块是一个将编码器和解码器数据相关联的多头注意力层,其中的V、K来自于编码器的输出结果,Q则来自上一层解码器中注意力层的输出。
2.LSTM模块
LSTM是一种常见的循环神经网络(Recurrent Neural Network, RNN)结构。循环神经网络一般用如下公式描述:

其中xt为当前层在时间步t输入的隐状态,ht为该层经过一定运算的输出,而ht-1是上一个时间步当前层的输出,f表示神经网络的运算函数,实现方式有多种。在本实验中,每一个时间步的输入即代表一个汉字经过编码的隐状态。从该公式可以看出,每一个字的输出都显式利用了上一个字(时间步)的输出结果,这也和人阅读文字的顺序类似。
LSTM即是对循环神经网路中的函数f的一类实现,它引入了一些门控单元,同时引入记忆单元,来实现对输入和输出更好的调节。为了实现更好的效果,我们使用了双向LSTM网络(Bi-LSTM),每一层的输出都是从左向右和从右向左两个不同方向LSTM的结果相加。
3.BERT+CNN模块
BERT模型由多个Transformer层堆叠组成,其架构类似端到端Transformer模型中的编码器。它一般被用于在大量无监督数据(即无标点符号的数据)或半监督数据(即包含无标点符号的数据和有标点符号的数据)上进行特定任务的预训练,让模型自己从大量语料中学习到底层和中层特征;随后在小规模监督数据上进行微调训练,通常能获得比在小数据集上直接训练更好的效果。模型在预训练阶段完成两个任务:掩蔽语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。MLM的训练方法,是随机遮盖一定百分比的输入词汇,然后让模型通过这些词已知的上下文,学习预测出这些被覆盖的字,该任务与Word2Vec任务中的CBOW[14]学习目标相似。NSP则是让模型判断出被随机拼接在一起的两句话,是否在原文中是连续的两句。不过,近来的共识[15]是在训练时加入NSP目标会对准确度有负面影响。
为提升预测效果,本实验在BERT模型后还加入了一层一维卷积(CNN)模块。CNN模型对编码器输入的句向量,在时间步维度上进行一维卷积,对句子中的特征进行提取,有助于捕获短程依赖关系,降低错误率。在CNN模块之后也添加了池化层,最后通过分类器得到最终标点结果。
三、实验分析
(一)数据集
数据集包括训练集和测试集,所述原始语料均为已出版古籍的电子版文件,均从中华书局经典古籍库[16]中提取。
1.训练集及预处理
从原始语料中提取约10亿字古籍文本(总共包含3,396种书目)作为训练集进行训练,四部类分布情况如表1所示。在对不规范语料进行筛选(如书目段落内逗号和句号的比例不达标即对文本进行删除)后,剩余5亿余字。总共生成近500万个段落用于训练集,1万个段落用于验证集。最后,清除古籍中不可能存在的标点符号后,对文本进行格式转换,处理为模型训练时的所需数据格式。

2.测试集
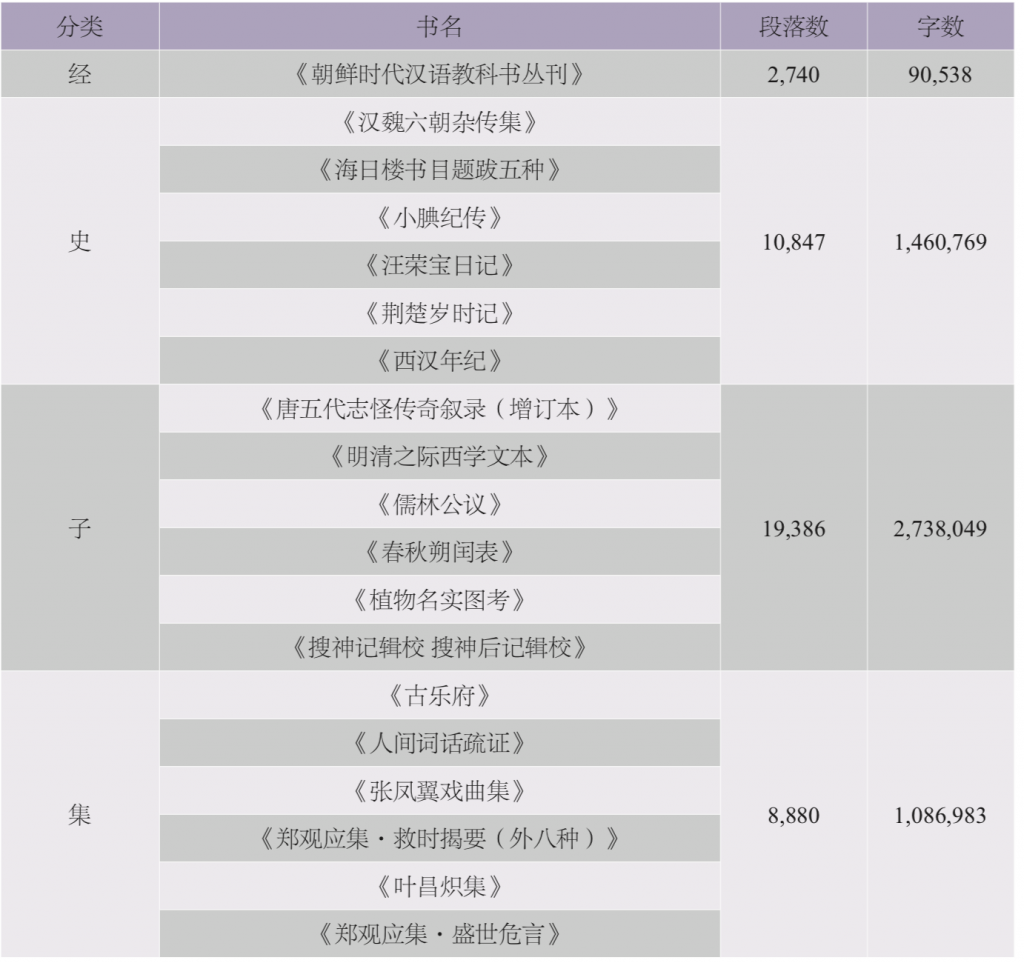
由于训练的语料多为常用经典文献,模型在这类语料中已有较好的表现。为测试模型的泛化能力,查看模型对训练集中语料不够多或者未涉及到的文体的预测效果,我们特意从未用于训练的原典语料中,抽取了与训练语料有一定偏差的19种古籍作为测试集。如经部小学类的《朝鲜时代汉语教科书丛刊》能反映从元末到清末的汉语实际口语,而又非中国本土所固有;史部着重测试纪传体正史以外的杂史类、政书类等;子部既挑选了专业性较强的天文类《春秋朔闰表》,又挑选了偏通俗、口语化,反映汉语史变迁的小说类作品,甚至包括《明清之际西学文本》这类新学文献;集部一方面挑选时代跨度大的总集,如《古乐府》,另一方面挑选实际语料体量极大,且语言风格和内容丰富多样、训练语料难以全面覆盖的戏曲类,如《张凤翼戏曲集》。
对抽取的19种书目,按照经史子集四部进行分类测试。因10字以下的段落句义不太完整,所以仅使用10字符以上(包含标点)的段落作为测试内容。最终剩余500多万字作为测试集。表2为筛选后的测试集书目表及相关信息。
(二)模型参数
本文使用的Transformer模型是基于fairseq开源框架[17]实现的。在训练参数设置中,编码器设置为10层,隐状态维度设置为768维,前馈网络隐状态维度3,072,每个神经模块的注意力层有12个多头注意力头;解码器为隐状态512的4层Transformer层,其中多头注意力模块为有8个多头注意力头。模型的层归一化(Layer Norm)模块采用和Transformer原论文一样的后置模式(Post-LN),并使用Liu等[18]作者提出的自适应初始化方案提升模型训练的稳定性。在模型训练中的优化器为radam[19]优化器,使用inverse-square学习率下降方案,最高学习率设置为0.0006,warmup-updates设置为单个epoch的更新次数,所有dropout值都为0.2。
此处使用的LSTM模型也是基于同样的fairseq开源框架进行修改后实现的。LSTM模型仅使用编码器部分,其中编码器隐状态维度设置为512维,编码器层数为6层。在模型训练的超参中,优化器为nag优化器,初始学习率为0.25,dropout值设置为0.1。
BERT模型使用了33亿字的殆知阁[20]古典文献语料,在对汉字进行分字、掩码标记后进行训练,我们未对于该语料中的未标点数据进行额外处理,将其同有标点的数据一样进行训练。MLM的训练数据掩码策略与BERT模型原论文保持一致,模型隐层设置为12层,注意力头数为12,隐状态维度为768。在微调训练的参数中,初始学习率为0.00002,dropout值设置为0.1,CNN层卷积核数设定为3。
因为BERT模型使用了预训练数据,而其他两个模型未使用,故我们对LSTM模型和Transformer模型使用了数据增强方案:我们将同一篇文章内的连续段落拼接成字数接近但不超过某一值L的长度,其中L每次取值从[100-设定的模型最大句长]整数区间中随机按均等概率选取。当一篇文章结束,或已完成当前长度L的拼接,则重新随机选取一新的L值。拼接后的数据与原数据按1:1合并训练。
(三)评价指数
自动标点技术的目的是为无标点古籍文献填充现代标点,评价为依据模型对测试集古籍的断句及标点预测与出版古籍标点的匹配程度。所以采用精确率(precision)、召回率(recall)以及F1值作为评价模型标点及断句预测的效果指标:

其中,TP、FP和FN源于混淆矩阵。TP为模型预测与原文中完全匹配的标点数量,FP为模型预测出来但原标注中没有标点的数量,FN为原文中有但模型没有预测出来的标点数量。TP+FP等于模型预测出来标点的总数量,TP+FN等于原文中存在标点的总数量。
此外,分类预测结果为根据四部类分类将测试文件整合为经、史、子、集共四个文件,对每个文件进行预测,并根据该文件中标注正确或错误的标点数据按公式(6)进行F1值计算。
(四)实验及结果
本文使用了相同的数据集对基于RNN的双向长短时记忆模型(Bi-Long Short Term Memory, LSTM)[21]和BERT+CNN模型进行了训练,并使用相同的测试集对其进行测试。三种模型对测试集标点及断句预测的结果对比,如表3所示。
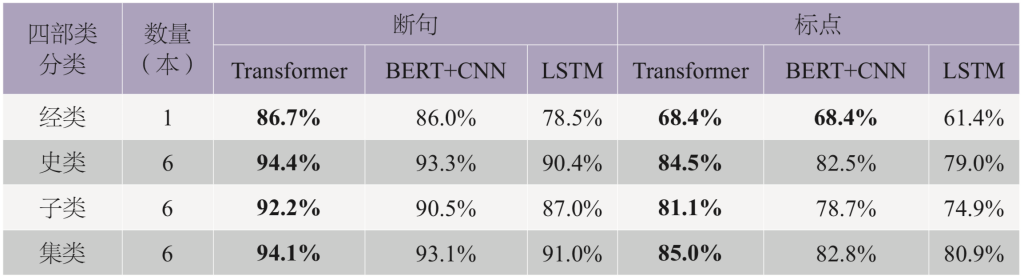
由表3中的结果可以看出,Transformer模型的预测结果在四部类的标点和断句任务上都获得了最好的成绩(在经类标点上的准确度与BERT+CNN模型同为第一)。在验证集上,Transformer模型的标点F1值为86.5%,断句F1值为95.1%,BERT模型的标点F1值为84.7%,断句F1值为93.8%。我们没有测试双向LSTM模型在验证集上的准确度。
从分类结果上来看,集部的预测结果在三组模型的标点任务中都高于其他分类的预测结果,经部的预测结果在三组模型的标点、断句任务中都普遍低于其他分类的预测结果。结合训练数据集分布中,集部的训练数据最多,而经部的训练数据少于其他分类的情况来看,可以推测,增加其他分类的训练数据可以在一定程度上进一步提高模型对文本预测的F1结果。经部结果较差,主要也和所选择的经部测试数据样本较少(只有一本)且偏向白话文本类型有关。Transformer模型在史、子、集类测试集上标点任务的F1准确率领先BERT+CNN模型的幅度比在验证集上的领先幅度稍高或持平,这可能也说明端到端模型的泛化性能会比单编码器类型的模型更好。
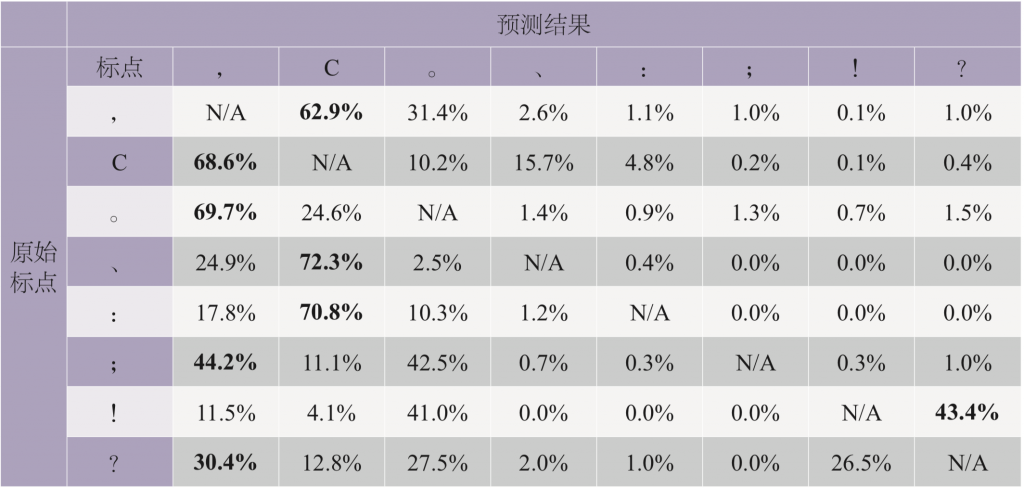
此外,我们对Transformer模型预测出来的错误数据做了进一步分析。通过对比数据中的原始标注和预测标注,查看模型主要对哪些标点进行了错误标注,结果如表4所示,其中的数值表示每个原始标点(左列)被错误标注成某一类标点的概率。从混淆矩阵的结果来看,模型更多的错误(占比在50%以上,见加粗数据部分)出现在:
(1)将逗号、顿号和冒号错误地预测成了无标点符号;
(2)逗号和句号之间产生互标,出现断句F1得分大幅高于标点得分的结果。
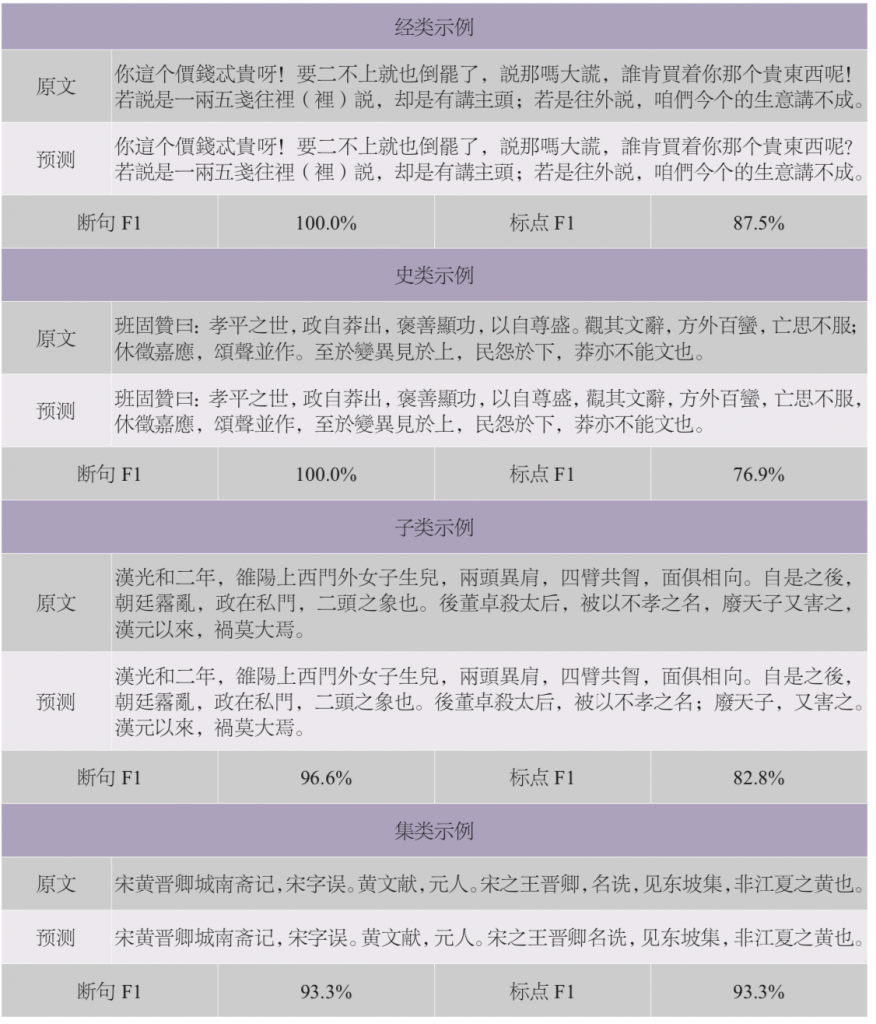
Transformer模型例句示例如表5所示,包括经史子集测试集中挑选出的原文、模型预测结果和通过公式(6)计算得到的断句和标点的F1值。
总 结
本文提出了一种基于Transformer的古籍自动标点模型,可以有效利用语料信息进行对无标点文本的标点(点号)及断句预测。点号的标注也可以被转化为自然语言问题中的序列标注问题。现有模型在验证集上,获得了目前我们已知方案中最高的准确度(虽然不同难度的训练文本类型会导致验证集结果存在差异),并在抽取的测试集上展示出了良好的泛化能力,集部结果更优。不过,大量数据在提升模型学习能力和预测结果的同时,也因不同书目存在不同编辑,所以可能存在同一句话有不同标点标注的方式,从而会影响模型整体的预测准确率上限。
并且,根据实际使用情况得到的反馈可知,模型对《黄帝内经》等经典古籍预测结果正确率极高;从对其他古籍文本的预测结果看,模型对书名和官职等部分的断句都十分准确。通过模型的平均成绩和实际使用的反馈结果可以看出,Transformer模型基本学到了训练集所包含的大部分语义信息和现代人对古典文言文标注的规则方法,但对近现代语料进行标点的表现上还是有上升空间。
在未来的工作中,将考虑清洗训练集中相同句子不同标点标注的情况,并加入更多近现代训练语料,以进一步提高模型的预测结果。
———————————————————————————————————————————————————————————————————
An Automatic Punctuation Method Based on the Transformer Model
Hong Tao, Cheng Ruixue, Liu Sixi, Fang Kaiqi
Abstract: In order to facilitate modern people’s understanding and learning of ancient books and documents, people begin to add punctuations in ancient scriptures manually, which means modern punctuations will be used in ancient scriptures without punctuations. But the number of ancient scriptures is huge and manual annotation is a laborious task. With the rise of artificial intelligence (AI), we can realize automatic punctuation based on deep learning. Therefore, the burden of manual annotation can be lifted. The Transformer model based on multi-attention mechanism is used as the automatic punctuation model to train 1 billion words from published ancient books. The model can achieve 86.5% on punctuation F1 and 95.1% on segmentation F1 on the validation set. Then 19 books were selected from the untrained corpus as the test set, and the results show that the model is good at classical Chinese corpus, but has low validity for more professional and vernacular corpus.
Keywords: Ancient Scriptures; Natural Language Processing; Automatic Punctuation; Machine Learning; Deep Learning
———————————————————————————————————————————————————————————————————
编 辑 | 严程
注释:
[1]郑永晓:《古籍数字化与古典文学研究的未来》,《文学遗产》2005年第5期。
[2]黄建年、侯汉清:《农业古籍断句标点模式研究》,《中文信息学报》2008年第4期。
[3]李铎、王毅:《关于古代文献信息化工程与古典文学研究之间互动关系的对话》,《文学遗产》2005年第1期。
[4]张开旭、夏云庆、宇航:《基于条件随机场的古汉语自动断句与标点方法》,《清华大学学报》(自然科学版)2009年第10期。
[5]J. Lafferty, A. McCallum, F. Pereira, “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data,” Proceedings 18th International Conference on Machine Learning, USA: Morgan Kaufmann, 2001, pp. 282-289.
[6]Z. Huang, W. Xu, K. Yu“, Bidirectional LSTM-CRF Models for Sequence Tagging,”arXiv:1508.01991,2015.
[7]M. Schuster, Kuldip K.Paliwal, “Bidirectional Recurrent Neural Networks,” IEEE Jounals, vol. 45, no. 11, 1997, pp. 2673-2681.
[8]俞敬松、魏一、张永伟:《基于BERT的古文断句研究与应用》,《中文信息学报》2019年第11期。
[9]Jacob Devlin et al.“, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” NAACL, USA: Minneapolis, 2019, pp. 4171-4186.
[10]A. Vaswani et al.“, Attention is All You Need,” Advances in Neural Information Processing Systems, USA: Long Beach, 2017, pp. 5998-6008.
[11]A. Krizhevsky, I. Sutskever, G. Hinton,“ ImageNet Classification with Deep Convolutional Neural Networks,” In Advances in Neural Information Processing Systems, 2012, pp.1097-1105.
[12]中华人民共和国国家质量监督检验检疫总局中国国家标准化管理委员会:《GB/T15834―2011标点符号用法》,北京:中国标准出版社,2012年。
[13]Ilya Sutskever, Oriol Vinyals, Quoc V. Le, “Sequence to Sequence Learning with Neural Networks,” NIPS’14, vol. 2, 2014, pp. 3104-3112.
[14]T. Mikolov et al., “Efficient Estimation of Word Representations in Vector Space,” Computer Science, 2013, arxiv.org/abs/1301.3781v3.
[15]S. Aroca-Ouellette, F. Rudzicz,“On Losses for Modern Language Models,” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), October 2020, arXiv preprint arXiv:2010.01694; Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretrainin Approach,” arXiv:1907.11692.
[16]http://publish.ancientbooks.cn/docShuju/platformSublibIndex.jspx?libId=6.
[17]https://github.com/pytorch/fairseq.
[18]Liyuan Liu et al., “Understanding the Difficulty of Training Transformers,” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), https://www.aclweb. org/anthology/2020.emnlp-main.463.pdf.
[19]Liyuan Liu et al.“, On the Variance of the Adaptive Learning Rate and Beyond,”arXiv:1908.03265.
[20]http://www.daizhige.org/.
[21]S. Hochreiter, J. Schmidhuber,“Long Short-term Memory,” Neural Computation, vol. 9, no. 8, 1997, pp. 1735-1780.
原刊《数字人文》2021年第2期,转载请联系授权。