您正在访问旧版存档页面。This is the old version archive of our site.

以搜韵网为例谈诗词知识图谱的构建与应用
诗词是文学的一部分,故其知识图谱的构建既离不开与其他文学作品共有的知识,又具备……
作者: 陈逸云 ;转自:公众号 DH数字人文
Infrastructure

陈逸云 / 搜韵网
—————————————————
摘要:诗词是文学的一部分,故其知识图谱的构建既离不开与其他文学作品共有的知识,又具备诗词特有的知识。以后者为主、前者为辅,可以将诗词相关知识数据化并建立关联以构建诗词知识图谱。搜韵网长年实践并开发的基于诗词知识图谱的应用软件成果,现每年约有来自560万台设备超过3.2亿次的访问量,是体现诗词知识图谱价值的典型个案。
关键词:诗词 知识图谱 搜韵网
—————————————————-
中国自古是诗国,几千年来的积淀,为后人留下了数以百万计的作品。据《中华诗词发展报告(2018)》,“2018年,我国从事诗词写作的人数已达350万”,[1]可见时至今日,从事诗词创作的人数仍比较可观。至于非创作型的一般诗词爱好者,则更是多不胜数。开设中文专业的高等院校,也都有从事诗词研究的学者。因此,如何挖掘利用古人的成果,构建并研发基于诗词知识图谱的应用为前述用户服务,有着重要的社会意义及学术价值。
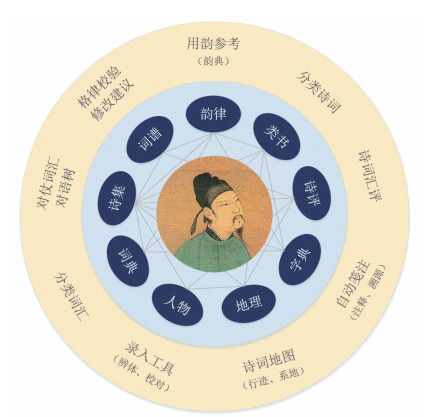
图1是搜韵网诗词知识图谱及其应用的示意图,包括以用户为中心(内环),以诗词及相关知识结构为图谱(中环),以用户需求为根据开发出一系列应用(外环)。
一、诗词知识图谱的构建
图2展示了搜韵网构建诗词知识图谱的技术路线。对诗词库(约950,000首)的数据化,主要目标是确定其体裁,分析其用韵,提取其对仗词汇,以及时间、人物、地理、用典、职官、植物等信息。

韵表、诗律、词谱、曲谱是辨体辨韵的主要基础。对于骚、琴操等体裁,由于其构成不易于程序化,则需要由人工来完成。如果辨体的结果是律诗,可从中间的对仗联,提取出对仗词汇数据。韵表主要以《佩文韵府》《词林正韵》和《中原音韵》三部书为基础。此三部韵书均未能收录所有汉字,因此需要依靠诗词库中的诗例以及《康熙字典》进行补充。诗律主要是近体诗格律。词谱及曲谱主要取清朝御定版本。
提取诗词作品或人物介绍中的时间、人物、典故、地理、职官或植物数据,则需要先建立各个领域的本体知识库。分类技术上,主要借助Trie算法,根据已建立的词汇库,先对文本进行分词,然后借助朴素贝叶斯和决策树技术,确定各类数据。以时间为例,表示时间的方式包括朝代、帝号、干支、月份、日、节气、节日、时辰等。对于每一类表达方式,需要先建立其本体数据,内容主要包括同位语、时间跨度、相关词汇等。例如,端午节的同位语有端阳、天中节、浴兰令节、蕤宾、重五、重午等,相关词汇则有龙舟、粽、菖蒲、艾草之类。同位语主要用于防止漏收,相关词汇则可用于根据上下文,增加朴素贝叶斯或决策树等人工智能算法分析结果的置信度。对于帝号类的本体数据,则还需包含其帝王信息、统治时长等。帝王信息又与人物本体关联。人物本体中的名号别称等信息,即成为以帝王统治时间纪年的同位语,如“汉高祖三年”“汉高皇帝三年”等。
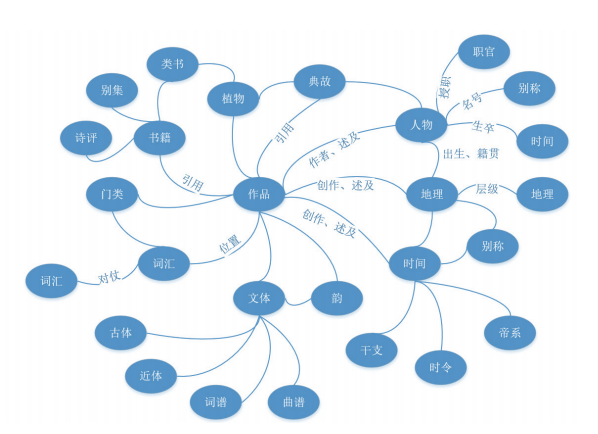
完成信息提取及结构分析之后,便可构造出图3所示的诗词知识图谱。
每一种本体,都是图谱中的节点。节点之间的边,用于记录各个节点之间的关系,如地理之间的层级关系、人物与作品之间的属主或一般述及关系、作品被各类书籍所引用的位置关系、词汇之间的对仗关系等。节点与节点之间,或直接或间接产生关系,各种关系或强或弱。节点之间互相交错,形成一个高维关系网络。为避免太多的线条交错影响可读性,上图中有一些关系没有标出。例如,典故因其出处,又与书籍有从属关系,典故中往往也涉及地理、时间方面的信息。书籍因作者及内容,又与人物、地理、时间有联系。这些关系在实际的搜韵数据库中,都是存在的。
二、诗词知识图谱的应用
应用主要来自于两方面:一是将构建诗词知识图谱过程中所使用的一些技术直接变成应用软件,二是根据知识图谱的成果数据,开发应用。格律校验即将用于辨体的技术直接变成应用;而校验结果的修改建议则是借助已经图谱化的数据,根据用户创作的上下文提供建议;自动笺注应用直接将数据分类技术应用到用户输入的任意文本上,并将分析结果与搜韵网的数据及资料自动关联起来,为用户提供丰富的参考资料;对仗词汇是典型的图数据,例如“天地”可对“江湖”“古今”“山川”等,而“江湖”又可对“风雨”“岁月”“日月”等;词汇节点之间因对仗关系而产生互联,据此可开发成启发式的对仗词汇查询工具,辅助近体诗词或辞赋的创作;已分好韵的诗句及词汇则可为创作者提供用韵参考功能;诗词中的分类数据,则为用户提供了按类别检索诗词的功能,其中的日期数据,开发成了诗词日历功能,地理数据则开发成地图类的一些功能,例如展示丝绸之路上曾有哪些诗人在哪些现存的景点上留下何种作品。限于篇幅,下面只着重介绍搜韵是如何从字、词、篇三个方面为用户提供辅助诗词创作服务的,其他功能可详参搜韵网站:https://sou-yun.cn。
用好韵字是诗词创作的一个难点。清代的《佩文韵府》按韵目提供韵字的倒序词汇及例句,为创作者提供用韵用词参考。但是,纸质书籍受篇幅所限未能尽举,且只提供倒序词汇,未提供正序词例,只提供本字在末尾的范例例句,未提供在其他位置的范例,字、词解释也未详尽,这些都是可改进之处。搜韵网的韵典功能,借助计算机技术将古今字典、词典、典故及历代诗词库熔成一炉,提供详细的字词解释、正倒序词汇和典故,以及韵字在句末和句中的例句参考。以“风”字为例,正倒序词汇便分别多达1,377个和1,056个,句末例句更多达1,660句,这已远远超过《佩文韵府》。然而,巨大的资料量也带来另一个问题:1,377个正序词汇,以什么样的顺序出现,最有利于用户找到自己想要的词汇?1,660个例句,应该以什么样的顺序出现,更能帮助用户?如果排列不恰当,那么可能用户找了几页,都找不到自己想要的。搜韵网的解决方式是,按词汇在历代诗词作品中出现的频度来进行排序。对于句末例句,考虑得则更多,包括末尾三字在历代诗库中出现的频度、作者的知名度、作品的体裁、句子在作品中的位置等。例如,同是来自名家的例句,如果这一例句是出现在律诗中的,那么比出现在古体诗中的,往往会具有更高的参考价值,因为律诗创作往往更考究句子凝炼。即使是同在律诗中出现的句子,也会因为句子的位置而产生差异。律诗中间两联往往因为要求对仗而更费锤炼工夫,参考价值一般也会高些。因此,搜韵提供的韵典功能,并不是简单的罗列,而是综合历代诗家、诗作、体裁等多种因素,通过人工智能优化排列的结果,从而达到更好地为创作者提供辅助的目的。
对于律诗创作者,中间两联对仗,是创作的另一难点。词语之间对得太近,可能有合掌之嫌,隔得太远,又可能有上下不连贯之病。鉴于此,搜韵网通过计算机自动从历代四十多万首律诗中进行学习、总结,开发出对仗词汇参考功能。在用户缺乏灵感时,可从古人的成句得到参考。例如,输入“天地”,便可得到415种前人用来与“天地”对仗的例子——“天地”可对“江湖”“古今”“风云”“鬼神”等。丰富的对仗例词例句,可为创作者提供很多参考与创作灵感。然而这也带来另一个问题,“天地”固然可对“古今”,但陈陈相因,也缺乏新味。如果能提供一些前人尚未使用过的对仗建议,那么会更有启发性与创新性。考虑到“天地”可对“古今”,“古今”又可对“南北”,“南北”可对“东西”,通过这样的递推关系,那么“天地”也可对“东西”,而且这一对仗,是古人所未使用过的。因此,搜韵网又借助这类递推功能,启发性地提供另外700多组前人未用过的对仗词汇,供用户参考。此外又提供对语树,方便仍不满足于此的用户自己进行探索。
最后,近体诗、词对作品的平仄和押韵皆有所要求。考虑到一些创作者对格律要求以及古代音韵体系并不熟悉,所以有必要借助计算机智能,开发能够对通篇格律要求进行校验的工具。搜韵网不止针对律诗和词都开发了校验工具,而且还能根据诗词库及词汇资料库,对于出律之处,按其平仄押韵要求提供修改建议。修改建议虽然未必尽皆合适,但是仍有参考价值及启发作用。这也是借助计算机人工智能充分利用前人成果辅助后人创作、学习的例子。
三、总结与展望
在诗词知识图谱的研发过程中,搜韵网一直以用户为中心,围绕着用户需求来进行研发,并通过用户反馈及访问数据不断提升质量。时下一些数字人文项目,直接围绕数据库进行研发,这容易导致项目成果难以落地,没有应用场景、没有用户反馈,难以形成良性循环。以搜韵网多年的行业经验来看,只有“问题、产品、用户反馈”三者形成闭环,才能让产品走得更广、更远。
在搜韵诗词知识图谱及其应用中,有很多技术同样适应于非诗词类的文本。特别是图2中述及的各类本体库和分类技术,可以很容易地应用到如古文献、史籍、小说等其他领域。事实上我们也正在进行此项工作,希望将来逐步建立起整个文史领域的知识图谱。
———————————————————————————————————————————————————————————————————
Development and Application of Poem Knowledge Graph: Take Sou-yun.cn as an Example
Chen Yiyun
Abstract: Poem is one form of literature. So, developing Poem Knowledge Graph not only needs knowledge of poem but also needs common knowledge of literature. This paper describes how to extract poem and poem-related knowledge meta data from poems and connects these data into a knowledge graph. Sou-yun.cn is built based on Poem Knowledge Graph developed by the author since 2009. At present, the website has about 320 million page views per year from 5.6 million devices from all over the world. This well illustrates the value of the Poem Knowledge Graph described in this paper.
Keywords: Poem; Knowledge Graph; Sou-yun.cn
———————————————————————————————————————————————————————————————————
编 辑 | 严程
注释:
[1]中华诗词研究院:《中华诗词发展报告(2018)》,北京:中国书籍出版社,2019年。
原刊《数字人文》2021年第3期,转载请联系授权。