您正在访问旧版存档页面。This is the old version archive of our site.

系列笔谈之二:古籍数字化平台的建设
DH Research Center of Peking University
徐永明(浙江大学人文学院):从传统古籍数据平台到智能古籍大数据平台
这几年,我主要从事结构化数据的建设工作,主要涉及“学术地图发布平台”及“智慧古籍平台”的建设。因此,下面主要介绍我对于从传统古籍数据平台到智能古籍平台转变的认识以及一些个人的试验性工作。
第一点,古代文献的价值。做事情要师出有名,做智能的古籍大数据研究必须对古代文献的价值有所认识。我将古代文献的价值概括为三个方面:认识价值、审美价值和功利价值。认识价值——古代文献可以让我们认识古代的社会,吸取相关经验教训;审美价值——众所周知,诗词、小说、戏曲等古代文献具备一定审美价值;功利价值——古代文献中,如“丝路文化”“唐诗之路”或地方名人等信息,具备文旅方面的功利价值。
第二点,当前文献的几种形态。在做学术研究时,会面临不同形态的资源——首先是金石文献、纸本文献等,其次是数字化文献,然后是结构化的数据,最后是智能化的数据。文献形态的演变过程就是从纸本文献,经过数字化,再经过结构化数据建设,最后到智能化数据形态。
第三点,现存古籍的数量。根据统计,《中国古籍总目》中有编号的古籍约十七万七千多种,分为经、史、子、集、丛五部。但《中国古籍总目》是几个大型图书馆的联合目录,并没有涵盖所有藏书机构及海外收藏,所以这一数据并不准确。后来国家又启动了古籍普查项目,对全国古籍进行普查登记。2021年底,据媒体报道的初步普查结果:我国的古籍有20余万种,60多万部,加上副本有270多万部。
第四点,数字化的古籍与传统的古籍数据库。数字化的古籍包括影像的数字化(Image格式)和文本数字化(Fulltext格式)两种类型。目前大约有10万种已经被影像数字化,文本被数字化的大约有4万种。当前不同类型的很多机构都在利用这些影像数字化、文本数字化的古籍,从事数据或数字平台的建设。根据建设者主体可粗略分类如下:个人建设的平台,如“中国哲学书电子化计划”(CTEXT),还有“书格”“国学大师”等;学术机构建设的平台,如加拿大麦吉尔大学图书馆Digital Initiatives团队设计的“明清妇女著作”全文专题数据库,香港中文大学中国文化研究所中国古籍研究中心建设的“汉达文库”,等等;公司参与建设的平台,如大家都在使用的“中国基本古籍库”“籍合网”“鼎秀”“四库全书”“书同文”“搜韵”“国学宝典”等数据库或平台。
这里顺便推荐安徽大学唐宸博士建设的“中国古典文献资源导航系统”。它的导航系统涵盖面也很广,除了数字平台以外,还包含目录、专题数据库、微信公众号等资源。大家可以通过这个导航进入各个网站,省去自己花时间收藏或记录。
传统的数据库有哪些功能和特点?我认为,一是可以全文搜索。通过搜索引擎可以全文快速搜索,给读者带来很大便利。二是复制粘贴,当前已经实现图文对照,文本正确率也相应提高。传统数据库的缺点是缺乏后台数据支撑,比如我们搜索到一个人名或地名,但缺少相关的介绍,地名也不能定位,关联功能是比较差的。因为结构化数据需要长时间的积累和建设,才能形成完整的智慧系统。传统数据库只是把古籍文本变为数字化文本,无需标点,也没有后台结构化的数据建设,学者参与度低,因此总体附加值较低。
第五点,结构化数据及平台建设。结构化数据就是把数据经过提取放到数据库里从而带有了很多的功能。常见的和文史相关的结构化数据库,包括哈佛大学建设的“中国历代人物传记资料库”(CBDB),浙江大学的“学术地图发布平台AMAP”,王兆鹏教授团队建设的“唐宋文学编年地图”。“AMAP”和“唐宋文学编年地图”都属于地理信息的结构化数据。此外,还有上海图书馆构建的“中文古籍联合目录及循证平台”,该平台具备一定的数字人文特征。其著录的书名、作者、版本等信息之间实现了相互关联,包括作者与其他人物之间的关联等,并形成相关图谱,同时具备地点在地图上的定位功能。
结构化数据的主要功能,一是可以计量统计,因为是群体的数据,结构化后可以进行计量统计或定性分析。比如CDBD中反映女性死亡年龄的图表,包含总的死亡年龄、平均数以及中位数,我们可以看出女性的死亡年龄高峰一是在青年时期,一是在老年时期。这可能映射出一些问题,诸如女性为什么在年轻时死亡率更高?——可能是由女性的生育或易代之际女性殉节造成。这种群体分析、定量分析只有大数据建成以后我们才能够看出来。结构化数据另一主要功能是定位查询和空间分析。“学术地图发布平台”发布的人物行迹图中,每个点上的信息都可以精准地定位,并显示出他的活动事迹。例如在汤显祖的行迹图中,我们可以看到他的活动区域。又如利用CBDB中的数据,对比唐代精英与北宋进士的籍贯,可以看到唐代精英主要分布在北方地区,北宋进士则南北都有。再如“全历史”网站[1]中可以根据时间来搜索并得到世界各国同时发生的历史事件。结构化数据第三个功能是可以进行社会网络关系的可视化呈现。比如朱熹、周必大、章氏三人的社交网络,从边的粗细可以看出他们当时的交往情况及影响力。再如分析袁枚和女性的交往关系,可以将CBDB中的数据导出后,用Pajek软件进行可视化呈现。
第六点,智能化数据及平台建设。所谓智能化数据,即利用知识图谱理念和大数据技术、结构化数据作为后台支撑,与古籍文本相关联,从而形成的集成性的数据及平台。目前正在实验的智能古籍平台有:MARKUS,是荷兰莱顿大学建设的可进行文本标识的平台;DocuSky,我国台湾“中研院”建设的带有智能性功能的平台;LoGaRT,德国马克斯·普朗克研究所关于中国古代地方志智能化数据建设的实践项目;还有“搜韵网”,其文本与词典关联,并提供一些知识图谱;北京大学王军教授团队建设的“宋元学案知识图谱”,是关于一部书的较精细的智能化数据;另有浙江大学在建的“智慧古籍平台”及上海外国语大学欧阳剑老师团队在建的“中国古籍基础数据分析平台”,等等。
MARKUS平台较早发布,能够利用后台的结构化数据对上传的文本进行标引,经过人工编辑,形成标引后的文本,同时与CBDB、CHGIS、TGAZ及维基百科等数据库进行关联。文本经过标引后,平台能够对标引的词进行解释或定位,并与图片关联。除相关工具书外,古代文献中有大量名目需要我们建设图片数据库,如《诗经》、《楚辞》、中医药相关文献等,需要图片和文本进行对应建设结构化数据,这是一个值得我们做的很大的课题。
“宋元学案知识图谱”是北京大学王军教授团队建设的一个智能数据实践项目。该平台对《宋元学案》里的词语、人物等进行了较精细的标引和智能化分析,能够看到某个学派的演变、发展的高潮与低潮等,还能够进行智能化分析。
“中国古籍基础数据分析平台”是欧阳剑老师以一己之力建设的,他在平台中添加了一些可以进行计量统计分析的工具,辅助用户进行文本挖掘。欧阳剑老师有计算机背景,又从事汉语相关研究,因此具备这样的能力。
详细介绍一下由我主持的正在实践的“智慧古籍平台”(csab.zju.edu.cn)。平台建设的思路是将古籍从图像转成文本,通过后台的结构化数据进行标引,最后展现给读者使用。具体的步骤就是将古籍文献通过OCR识别,进入智能的古籍标点环节,然后采用众包的方式进行人工校对,文本通过审核以后,再进行机器标引、人工标引及核校,最后发布出来。标引完以后,文本中的词语就跟后台的工具书关联起来。这就是我们建设第一期数据的大致框架。
我们在首页每天发布一些新的数据,发布完成后可同步到前端。前端功能主要有:著述导览、篇目导览、作者导览、专题导览、关系图谱导览、地域导览(待建)、主题词导览(待建)、时间轴(待建)、校注版(待建)等。
著述导览中可以看到著述的目录。著述按照经、史、子、集、丛分类,在平台按照分类进行整理和发布。传统数据库中,篇目的标题多放在正文中,但我们将标题提取出来做成表格,并标注标题的文本属性,如标注某篇文章的文体属于序,或墓志铭,或行状等。
著述标引完成后,采用不同颜色来显示标引实体的不同类型。如需要查看标引实体的含义或地点,打开平台的关联功能则可实现。对于一些未被标引的实体,平台也提供划词查询功能,如果后台工具书有对应条目,则会显示该词的意思。平台提供公元纪年与传统纪年转换功能,用户无需另去查核工具书。过去我们多使用陈垣先生的《二十史朔闰表》,而现在通过计算机可以直接转化。平台提供地名定位功能,如果某地点在“中国历史地理信息平台”等没有相关信息,我们则可以临时在后台进行信息维护,随时对该地点定位。此外,平台还提供词语的英文解释,如《红楼梦》中“甄士隐梦幻识通灵”的“通灵”一词,平台提供其英文释义,这对于外国读者阅读或我们学习英文很有帮助。当前后台也准备载入《汉英词典》数据。
此外,平台还为每一本著述添加提要及知识图谱。如墓志铭、行状多蕴含世系关系,后台做世系图十分方便,只需添加人物关系就能生成可视化的效果,无需另行绘图。绘图完成后,则附于著述之后,如用户后台工具书包含该人物的传记或其他信息,则能在世系图的人物详情中展示。
篇目导览中能够显示篇目的文体,如文、诗、词、曲、小说等。如果想要知道“寓言”有哪些,那么点击“寓言”选项,不同子集中被标注过的寓言都会显示出来。此外,我们可以进行全文搜索,也可以按篇目搜索,第二期建设会增加正则表达式搜索。平台还提供图文对照,以及词云、关系图谱等功能。
作者导览中,可以按照音序、生卒年、ID号对作者进行排序。过去编修总集的难题是进展缓慢,如编纂《全明诗》需要很多人参与,假如缺少某人的资料,或某个人没有完成工作,那么整个工程就处于停滞状态。现在利用“智慧古籍平台”编纂总集,工程进度更有保障。按照人物的生卒年对作品进行排序十分方便准确,缺少生卒年信息的人物则依据与他大约同时代在世的人物生卒年来确定指数年进行排序。人物专辑则包括小传、名言、著述目录等信息。第二期建设会增加人物现存著述的所有版本的目录,以及相关的图片、行迹图、图谱等。
专题导览主要包涵一些不能够单独归类的信息,包括分布图等,日后还会增加一些讲座视频或专题著述。图谱导览可以查询人物世系图或社会网络关系图。从2021年11月到2022年3月,平台已陆续发布三十多部书——利用众包系统,整理进展非常快——过去是“个人作业”,如今是“集体作业”。著述详情主要显示一些我们自主维护的基本信息,包括书名、作者、版本、朝代、收藏地、著述提要等。
篇目库中,古籍整理成果发布后按照篇目呈现。在众包系统中也是按篇目来整理,而不是按照某部书的前后顺序。如果某位整理者选择了某书的某篇,第二人则无法再选择此篇。之后在整理所选择文本的过程中,平台有待校对、待审核、审核通过、审核未通过等图标以显示不同的整理状态。校对界面提供图片和文本以方便整理者校对,校对完成后则可提交。如果一篇文章很长,不能一次性完成,可以保存进度,也可以放弃审核。针对标引,后台提供了很多工具书,可以人工选定对应的词典进行标引。当然需要先要经过机器标引,否则人工标引的工作量是非常大的,同时机器对于地名、人名的识别标引准确性非常高。
工具书库,为维护各类人名库、时间库、名目库等提供支持。我们可以临时创建工具书库、增加词条来对工具书进行维护。现在我们引入了智能OCR识别——阿里云文字识别。上传图像后,通过OCR识别可以读取图像中文字,经过人工的校对,就可以进入机器标点。整理成果发布后,可选择“游客可见”使用户可见,或锁定实体即锁定图谱中一些人物,不允许编辑,来进行维护。
接下来介绍用户管理。国内用户通过手机号码注册账号,国外用户可通过邮箱注册账号。平台可授权用户各种权限,包括审核权限、标引权限、校对权限等。
总的来说,我认为传统的数据库经历了结构化数据向智能化数据演进的过程。智能数据库建设更需要学者参与,而传统数据库学者参与度较低。传统数据库主要是把扫描后的图片转成文字,那么只要会五笔字型,对着图片校对就可以了,不需要标点。然而,智能数据库能够利用众包系统进行线上古籍整理,再加上结构化数据建设,从而提高文献的附加值,这都需要学者的参与。
智能化数据或平台,其智能表现在哪些方面呢?一是智能OCR和智能标点;二是机器的自动标引;三是智能的搜索形式,包括正则表达式,甚至时间轴里的时间、地点、人物、事件的关联搜索;四是众包技术,我认为众包技术对古籍整理是非常有用的,如果按照传统方法,《全明诗》《全明文》《全清诗》《全清文》等是很难整理的,我们这代人可能看不到最终成果,但利用众包技术,只要国家支持,我认为我们这代人是很可能看到它完成的。
因为现在有知识图谱技术,平台需要整合图数据库来展示世系图、社会网络关系、思维导图等。比如我们想把某一著述的主要思想观点拎出来,可以通过思维导图的方式可视化呈现,然后将其中的地名定位在地图上,还可以关联词典、多媒体。多媒体包含视频、音频等,如戏曲中的曲牌、唱法,只要将视频和曲牌进行关联,用户就能够即刻听到或看到。智能还表现在人机互动领域。人与机器实现互动后,机器可能可以回答我们提出的问题。当然现在还有元宇宙技术,运用虚拟技术,一些故事性的文本也可以通过虚拟场景体现,从而增加我们对文本的认识。
因此,我认为传统的古籍整理与我们在大数据背景下利用各种技术进行的古籍整理有很大不同。传统的古籍整理主要是个体作业,以书为单位,依靠个人能力完成,出版后不能修改,也不可关联实体。大数据整理平台则具备完整的生态系统,包括众包技术、可关联技术等,以篇目为单位进行整理,人机共同完成,随时可以修改。大家都知道,现在《全唐诗》《全唐文》《全宋诗》《全宋文》《全元诗》《全元文》都已整理出版完成,当然也还在不断地修订,可能会再出版增补本。除了《全明诗》《全明文》《全清诗》《全清文》等大型古籍整理项目外,还有大量的明清别集需要我们去整理,任重而道远。我们希望利用“智慧古籍平台”,加速这些古籍的整理进程。
王兆鹏(四川大学文学与新闻学院):古籍数智化的意义
我先解释一下为什么用“数智化”概念。数智化,实际上是“数字化”和“智能化”的二合一。“数智化”是我自己想到的一个概念,但上网一查,发现已经有人说过了,所以这个概念的首创权不是我的。因为古籍智能化是以数字化为基础,所以我想要把这二者结合起来,于是用数智化的概念,以求简明。大家对智能化概念更熟悉,而对数智化概念要陌生一些。
古籍数智化的意义是双重的,一是功能性提升,二是结构性转变。功能性提升,看得见摸得着;结构性转变,则是深层的变革,具有范式意义。
功能性提升,可以概括为三点:第一是OCR自动识别,由纸本文献自动转换为数字化文献,这样可以迅速扩大数字化转换的规模。第二是自动标引,第三是自动校注。北京大学和中华书局都在开发完善古籍自动标引的技术。我想结合我们团队开发的“知识图谱”简要介绍一下自动校注。“知识图谱”是我和陈逸云先生合作,而由陈逸云主持开发的。古籍自动标引后,有了自动校注功能,就可以降低古籍的阅读难度,这实际上扩大了古籍使用的广度。
自动校注,包含“校”和“注”两个方面。校,是汇校不同的版本。校勘,本是一门专门的学问,未来校勘学有被计算机替代的可能。首都师范大学周文业先生,近年来一直利用数字化平台来汇校各种小说版本,把《红楼梦》《水浒传》《三国演义》等各种版本并列在一起,运用计算机来自动比对。字词之外,连标点、分行、分段,计算机都能够校对比勘。人力做汇校工作是很辛苦的,计算机来做汇校工作,既准确,效率也高。我们的知识图谱,也可以进行各本汇校,而且可以图文对照,即原书图像和转换的文字进行对照。只是目前的版本资源有限,汇校的优势没有显现出来。
注,是字词的注释。徐永明先生开发的古籍智慧化平台也有这个功能。知识图谱平台诗词库里所录作品,都有自动注释功能。以杜甫《登高》为例,诗中凡是划了横线的词语,都是有自动注释的,点击它,注释就会呈现。现在的后台资源,只有《汉语大词典》。今后,如果后台资源里收录有杜诗的各种注本,就可以将各家的注释汇列一处,供用户选择,看哪家注释最完善,最切合诗人的原意。如果韩愈的诗歌注本、苏轼的诗歌注本里也有同样的词语,计算机也可以和杜诗的注释关联到一起,供用户参考。计算机也可以结合文本的特殊语境推荐优先级的解释,即“一词多注,优选推荐”,用户当然可以自己选择最优的解释。总之,今后汇校、汇注工作,都可以用计算机来完成,至少计算机能为我们做相当部分的工作,专家只是最后把关。有些模糊歧义、计算机处理不了的,人工来干预。这会大大降低文献研究者的劳动量。这就是功能性提升。
所谓结构性转型,可从两个角度来看,一是知识的贯通化,二是数据的聚合化。知识贯通,是从分隔到融合贯通。古籍的知识体系,分经、史、子、集四部。打个比方,四部相当于四栋大楼,经部一栋,史部一栋,子部一栋,集部一栋。每栋大楼里又分很多层,每一层又有很多房间,每一房间有很多柜子,每个柜子里有很多抽屉。每个抽屉里存放着分类有序的各种知识史料。对于普通读者来讲,不知道每栋楼每个抽屉里存放着什么知识、什么史料。知识和史料是被分离隔开的。智能化数据库,能够打通这些知识之间的分隔,让知识的大楼变成透明玻璃屋,让我们一眼洞察每栋大楼、每个抽屉里存放的知识,而且能让每层楼房、每个柜子、每个抽屉之间都有双向的通道,让知识和史料自由地关联贯通。
今后的知识和史料,都会由过去的分隔逐步走向贯通。首先是时空的古今贯通,所有文献都有时间和地点的标识。时间有两种标引方式,一是时间点的标识,二是时间段的标识。时间点的标识,小到如杜甫的每一首诗写于哪一年。如果杜甫有些诗不能考证清楚是哪一年写的,就可以标时间段,也就是按杜甫的生卒年,标为712—770年之间。又比如我们不清楚《庄子》的创作时间,但庄子生活的大致时代是清楚的,那就把《庄子》所有作品的时间信息标识为前369—前286年之间。这样的标注,对于《庄子》研究本身可能意义不大,但如果所有的文献都有时间段的标识,那么,研究一个语词、一个概念、一个物象(意象、名物),了解事件的形成发展变化,就很有意义。特别是研究语言学里的语词概念,它原始的本义是什么?有哪些引申义,引申义是从什么时候开始延伸的?我们从字典里也能知道有多少种引申义,但哪个引申义在前,哪个引申义在后,就不太清楚。所有语料有了时间标识后,就可以按照时代先后来研究语义、概念、意象的变化。再比如用韵,我们都认可现在的韵部分类,但这是共时性地研究韵字、韵脚的不同,今后如果每一个韵部都有了具体的时间标识,那我们就可以考虑音韵的年代、时代变化。我们现在也注意到先唐、唐宋时期用韵的不同,但这个时间跨度过大,今后可以细化时间粒度。除了语词、概念、名物等变化之外,我们会对事件的变化、时代的发展变化了解得更加清楚。比如,知识图谱可将各种史料记载的中国历史上每年、每月、每天发生的事件、创作的作品都关联呈现出来,我们可以更深入细致地了解每个事件的来龙去脉、前因后果。比如,2020年为庚子年,在1.0版古籍数据库中检索“庚子”,可以检索到比较多的资料,但这些资料,既含有庚子年的资料,也有庚子日的资料,用户没法区分。而知识图谱可以按时间顺序,把每个庚子年的资料呈现出来。由于目前后台资源的限制,历史上不一定每一天都有事件记载。但只要数据库里有记载,平台就能全部列出来,如点击1180年九月,平台列出事件116次,再按照日期来分,就细化到每一天,可以看到每一天有哪些人在哪里活动。九月九日重阳节这天陆游在哪里?平台显示,陆游与周必正等人登高集会,地图也随之显示活动地点。这样时间和空间就关联起来了。知识图谱里的空间信息,按当下的省份来分类排列。各省之下按照地市来排列,市下面分区县。过去,在1.0版文献资源库里要查“四川”,只能查到包含“四川”两个字的信息,现在知识图谱里,既可以查到四川省全境的信息,也可以查询获取四川一市一县一乡一镇的资料信息。史料由市而县,由县而乡,一层一层地罗列,知识和史料都被有序化、条理化了。比如查唐宋时代有哪些人物在绵阳市梓潼县活动过?数据库显示,王勃在这里活动过,进一步点击,就可以详细了解王勃何年何月来到梓潼县,写有什么诗作。这是横向地点与人物的关联。
其次是打破部类的分隔,实现经、史、子、集之间的贯通。要查询一个人物或地点,经、史、子、集四部文献中的资料能全部汇聚到一起,而且不再是各自独立的条目,而是有序化的资料。同时诗词、文赋、小说等类别也在文学层面相互贯通。比如,过去研究苏轼一首词的影响,我们主要是从词里去考察,现在有了大型数据库,就可以考察一句词对诗歌、文赋、小说、戏曲的影响。各个文类之间都是相互关联、相互贯通的。这不仅仅是检索结果的贯通,也使人类知识视野实现了贯通。
数据的聚合化,是说原来零散的数据现在可聚合到一起,来发现新问题。1.0版数字资源库里也有一些数据,但数据是孤立零散的。2.0版数据库是关系型结构化数据库,结构化的数据是有序的,让数据从零散到聚合。我们初建唐宋文学编年地图平台的时候,人们更多的是关注平台的功能,其实平台最大的意义,不仅仅是让用户去检索资料,而是能够满足大数据时代对文学大数据的需求,在平台发现、挖掘、提炼出各种类型的数据。
前不久,《光明日报》理论版刊登了清华大学刘石教授和“国学宝典”创始人尹小林先生合作的论文《以数字映射古代文学经典》,文中举了大量数据来验证一些经典的结论,利用大数据来映射中国文学的经典。[2]我在同日同版的《光明日报》也发表了《大数据里的唐宋诗词世界》,指出数据的意义既可以验证现成的结论,也可以颠覆、改变传统的认知和结论。[3]举个例子,按照现代地市州的行政区划来统计,宋代哪个地方的作家最多?大家可能想到北宋京师所在地开封府最多,或南宋都城所在地杭州最多,抑或是经济文化发达的扬州、苏州这些地方。我们统计相关数据后发现,上述这些地方都不是,而是福建南平。这大大出乎我的意料。为什么是福建南平?福建南平地远偏僻,为什么会涌现那么多作家,文学为什么如此发达?北宋大词人柳永和南宋首任宰相作家李纲,都是南平人。我再去找其他数据,看看这个结果有没有道理。于是,我去统计宋代进士数据,看宋代哪个地方的进士最多。数据统计结果显示,宋代进士最多的地方,也是在福建。福建福州的进士数量全国第一,南平的进士数量全国第二。与此相关,宋代福州的作家数排在全国的第二。也就是说,宋代作家和进士数量位居前一、二名的,都是南平和福州。这两组数据表明,文学的发展与教育的发展密切相关。这给我们古代文学和历史研究提出一系列问题:两宋时期为什么福建南平和福州地区的文学、教育都很发达?这两个地方的文学,经历了什么样的发展历程?起点在什么时候,什么时候进入高峰状态?是谁引领和造就?这些问题,值得我们去探讨和回答。再比如作家社会关系网络图,它的意义不只是由过去的表格变成现在很炫酷的图,而在于其背后深藏的学术意义和历史意义。比如,在唐宋以后的诗词中,哪些先秦人物被提及最多?影响最大?是老子?还是孔子?我们会想到,中国古代文化以儒家为主导,应该是孔子。但在诗词世界里,孔子的影响力不及老子。唐宋以来的诗词,提及老子的数据是2,300余条,而提及孔子的数据只有1,020条,孔子的影响力似乎不及老子的一半。屈原和陶渊明两人谁的影响更大?按照当下主流的观念,我们肯定认为屈原影响更大,结果又大大出乎我们的意料。在唐宋以来的诗词当中,直接提到屈原名字的只有893条数据,而提到陶渊明的则有4,000多条数据。再比如中国古代的四大美女,哪位美女的影响最大?数据显示的是西施。这些数据非常有意思。我们可以研究孔子是什么形象,诗人言及孔子时关注他的哪个方面?老子的影响力又体现在哪个方面?是他的智慧,还是他的人生态度,抑或是其他方面?这也为我们提供了很多新课题。数据还能帮助验证一些规则。比如格律诗有所谓三平尾、三平调的规则,古人是否遵循这个规则?数据可不可以验证?也可以。我们依据知识图谱里诗词库抽样统计,唐宋以来创作格律诗30首以上的作者有1,224位、作品24万多首,出现三平尾的作品只占0.24%,而出现三仄尾的作品占6.7%。这说明三仄尾的律诗比三平尾的律诗更常见,也就是说,大多数诗人是守三平尾规则的,而三仄尾规则相对宽松,所以出现的频率比较高。大数据不仅可以验证某些结论,也可以验证一些规则。
智能化数据库,还能帮助我们创造性转化古籍资源,为文创产品的开发和文化旅游路线的设计服务。举两个例子,成都西华大学原副校长朱晋蜀团队,利用《论语》的大数据资源,开发了一系列带有《论语》元素的产品,从食品到日用品,既有趣味,也有实用价值和商业价值。我们团队帮助开封市文化旅游局开发了“词人陪你游开封”项目,让李清照、苏轼等著名词人现身说法,带着旅客线上线下游览开封各个名胜,沉浸式体验宋代的文化场景,也很有趣味。今后智能化古籍数据库,不仅给学术研究带来无穷的便利,也可以为文化创意和文化旅游提供无尽的资源。
欧阳剑(上海外国语大学图书馆):数字人文视域下的古籍基础数据应用平台实践
在此主要介绍一下我做的“中国古籍基础数据分析平台”。其实在2014年我就已经开始思考相关问题,当时采用的是一种传统的古籍开发模式(图1),还是以阅读功能为主。

图1 传统的古籍开发模式
首先介绍一下我当时做古籍开发应用工作的一些思路。传统的古籍应用基本上是以诸如图片或者文字的形式呈现,以传统阅读的模式来辅助我们做研究。当时我在做语言学相关的研究,希望有相关的平台做一些辅助分析。对于传统的研究,“中国古籍基础数据分析平台”可能在阅读上有所帮助,可以帮助我们搜寻资料,能精确并且迅速地找到想要的信息。但是从研究角度来看,利用“中国古籍基础数据分析平台”可能还是和传统的研究方式类似。能否用数字方法来辅助我们做研究?我们尝试让人文学者研究模式从读的方式转变为分析的方式,并且是基于数据的研究,这是当时我的研究思路。然后我们就根据当时的需求对平台进行了很多扩充,刚开始是引入文本分析,后来扩展到古籍相关知识,还涉及文本、图像等方面,努力达到古籍相关知识点的关联、融合。然后开始尝试能否在此基础上做一个中国古籍相关的基础的数据平台。这可能在很多研究领域都用得上,不限于语言学、文学、历史学,其他学科都用得上。这是当时大概的想法。对于能否实现大规模的古籍数据多元化、整体化的研究比较分析,而且从不同的维度来进行分析,当时我也做了一些尝试,用大数据的理念来探索古籍的研究方法。并且在这个基础上,是否能够把方法和工具进行具体化,为学者提供一些工具或平台?在做的过程中,实现文本化、数据化,然后知识化,这其实都是相关联的。这是当时我做古籍基础数据平台的一个出发点——生产一些辅助性的工具来帮助人文学者做研究,并为学者提供一些数据。
可能做过数据方面工作的老师都有这种体会,基础数据工作是很辛苦的,也没有太多创新性。我当时做数据主要从完整性、可计算性、可复用性,还有可发现性及可获得性角度去组织数据。对数字人文平台来说,基础数据也是最基本的,其次才是上层的一些研究方法、研究理念。这种方法最终要通过工具、平台来实现。
因此,在这个基础上,我做了一些探索性的尝试。数字人文视域下的中国古籍数据,它的组成主要有哪些?当时我根据自己的能力和一些构思,将其主要构成分成这几类:作品分成文本与图像、编撰者的相关信息。我把作品、编撰者两者之间的关系作为一个核心,真实范围还可以扩充。建设数据花了很长时间,当然也请了很多同学来整理,通过各种方式,但大部分是通过机器的方式来做的。数据主要有存世的古籍目录、编撰者信息。编撰者信息建设当时也花了很长时间,有的古籍编撰者很少被提及,找不到作者相关的信息,用CBDC来核对作者信息,可能也就只有几千个作者能够对得上,很多作者可能还需要通过其他的方式,利用人工去查找,作者需要跟他的年代、籍贯关联起来,只是建设这两项信息就花了很长时间。数据量方面,我们收集了全球700多家图书馆的数据。按照收集的数据估算,我国的古籍总数大概有六十几万种,约22万个编撰者、150万个版本,可能仍有一些图书馆的数据未包含在内,特别是国外的图书馆。
接下来就考虑平台建设。当时是从数据分析角度出发,而不是侧重于阅读模式。商业数据库的阅读模式已经做得很好了,从研究角度来讲,再做这方面的建设可能创新性就不足了。人文学者有精读的需要也有泛读的需要,我们当时从这两个方向出发,尝试做一些分析性的工具或者方法。
数据平台可以分成这几类:第一类是阅读,就是传统阅读模式,包括图片的阅读。第二类是知识服务,即我们能不能从知识角度来进行多维度的计算。第三类是常用的量化分析,比如词频等。第四类是文本挖掘。古籍文本分析其实也是我当时的博士论文的一部分。可能大家对文本分析研究模式都很熟悉了,特别是Google Ngram Viewer。其实当时我们也参考了它的研究理念,考虑我们是不是从一个大的尺度对文本进行呈现。这是从语言学角度来讲的,但是可能在其他的学科也会用得上。如果整个中国的文本量足够大,是不是可以找到一些词频分布的规律,是不是能够作为分析手段来进行研究?因此,当时我们就尝试采用这个方式来建设。
因为作者、古籍编撰者以及版本的问题,当时我们花了很长时间来做作者年代的校对。至于版本是哪个年代的,我是以作者所在的年代来进行判定的。从语言学词汇演化角度出发对中国的一些古籍文本来进行分析,如果从研究理念来讲,我们可能属于泛读模式,当然平台提供一些比如常规的图形展现的模式,即可以看到具体一本书中一个词汇的占比,也可以定位到特定数量、顺序的书。例如,只列出前面20种文献,一个词汇所占比例和年代的分布就展现出来了(图2)。下面的折线图中,这些点表示单个文本的词频量,折线做了一些简单的求平均和去噪点等计算。

图2 字词频率及分布
还可以查一个词,平台显示哪些作者写了这本书以及作者在中国地图上的所在位置(图3)。当时考虑到古籍可能牵扯到方言,因此,我把一些作者的籍贯也映射到查询过程中。这是文献所在的比例分配,即查这个词的时候,它的相关文献主要分布在哪个朝代(图4)。
对一个词或者对具体的文献当中词的使用,我们可以定位到全文当中,而且可以定位到相关字的位置来看前后的词句,可以从整句或者语言前后语境来判断词义,如果以传统的方式来看,这就属于精读模式。
我们也做了简单的分词功能,当时是用词库加马尔可夫模型来做的,以满足学者词频统计需要。在这个过程中陆陆续续建设了很多基础数据,特别是以古籍为基础的数据。
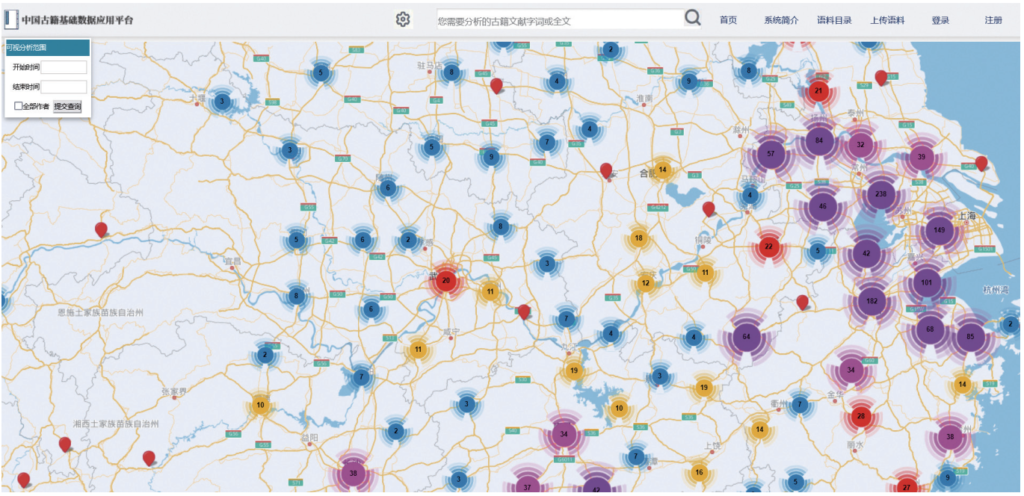
图3 文献编撰者在地图上的分布
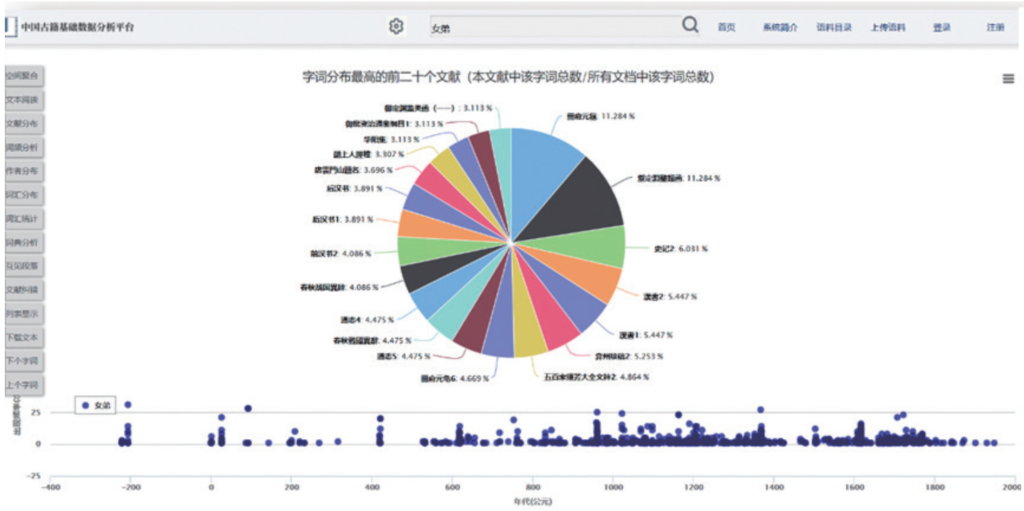
图4 字词在相关文献的分布
在数据的基础上,就扩展到了典籍的知识服务领域。我们尝试做一个中国存世典籍的知识图谱,然后以此为基础,可以在图谱上输入任何一个作者,呈现出作者相关联的作品、人物及信息,还有作品收藏地。这是可以以作品为中心进行无限拓展的,也即我们点击某个作品,与作品关联的人也联系起来。其实典籍图谱可以从分析角度做很多的研究,这不是我的研究重点,如果想在这个基础上做典籍分析,可能有很多研究工作可以做。如果从可视化呈现效果出发,当数据量大的时候,基本上浏览器就很难承载了。因此,有时候可视化并不是一种很好的方式,可能传统的统计方式会更好。这是作者的关联关系,即于图谱中作者之间有哪些关联,比如有的作者在他人的作品上进行了注、编之类的工作(图5)。

图5 典籍知识服务
还有时间、空间维度需要表现出来,诸如后代的人可能对前代的作品进行了编纂,相关古籍具体在哪个地方分布。现在其实很多学者需要一站式的古籍查询,因此,我们当时就从这个角度出发,采用了地理信息系统,做简单的古籍分布展示(图6)。
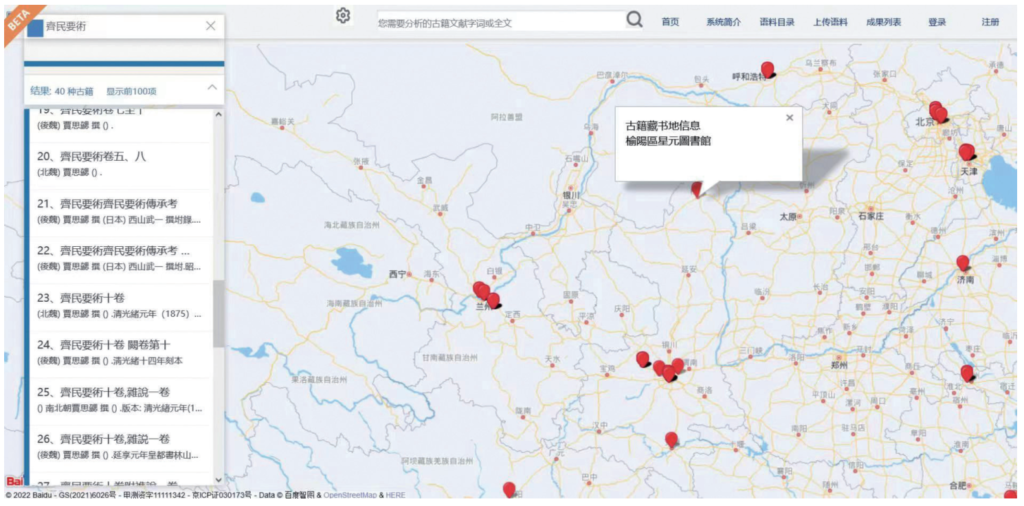
图6 典籍检索及分布
从语料库学角度来讲,查一个词,我们需要知道这个词在哪些文章当中出现,它在文本中的前后位置是怎样分布的。语言学的语料库可以辅助学者做古代汉语的一些相关研究。
从汉语词典这个角度来进行研究,比如《古代汉语词典》,是否能够在平台上辅助我们做在线词典编撰?是否能够结合我们的文本语料库的基础,在平台上做古代词汇的编撰?当时我也做了一些尝试。
这是我在数字人文视域下对古籍基础数据开发的尝试,希望对大家有所启发,有所帮助。我们的古籍平台因为牵扯到很多问题,所以还没有正式面向社会开放注册,但是对个别学者已经开放了,有学者直接联系我需要平台来辅助做一些研究,不久后平台会也对公众开放。
洪涛(古联(北京)数字传媒科技有限公司):籍合网古籍整理平台
我想从企业角度讲一讲对古籍数字化平台的理解。首先介绍一下籍合网。籍合网于2018年上线,是国家级古籍整理出版资源平台,由中华书局的全资子公司古联公司建设、运营。这里简单罗列一些籍合网的数据:籍合网上有31个数据库,涉及23个出版社的古籍整理出版成果;发布字数39亿,另有70亿字的古籍大数据中心;研发的中华书局宋体字库,有15万余字,包括了甲骨文、金文、梵文悉昙体、小篆等多种字形;籍合网的古籍整理众包平台有近5,000人参与众包工作,近年来我们发布了四万多个整理任务,处理了约14亿字的古籍整理资源;我们还有古籍整理培训课程,现在有42位作者参与了古籍整理培训课程录制,完成课程46门,还有一万余道古籍整理水平测试题;公司开发有古籍整理相关的智能技术,如OCR识别、自动标点、命名实体识别等;近年来为出版单位提供了约五亿字的编校服务,完成了约一千多万字古籍的引文核对;为出版社等相关机构提供数字化项目服务,处理了一千多册古籍;此外,还和高校建设了9个实习实训基地。我们的用户包括大学、公共图书馆、出版社等数百个单位,注册用户有20多万人。这是籍合网整体情况的介绍。可以看到,籍合网作为一个古籍数字出版平台,是一个非常复杂的系统。我就不再深入介绍具体的数据库和功能,大家随时可以到籍合网(www.ancientbooks.cn)上去使用。刚才所介绍的,也是为了引出我们今天讨论的话题——什么是古籍数字化的平台?
对我们企业来说,古籍数字化平台是一种商业模式,对于用户来说古籍数字化平台是一种生态环境。因此,在我们看来,古籍数字化平台不能仅有一类用户或一种功能,而应该是由多边构成的组织、多种类型的用户和多种用途交织在一起。我简单介绍一下这张业务流程图(图1)。我们最原始的出发点是从出版社的图书开始,对图书内容进行数字出版,从而建成这些数据库。在图的右上角,有一个在线的整理平台,包括了我们的众包工作办法和技术手段,整理平台向我们的数字出版输出一些新内容,这些内容同时也可以实体出版。最终所有的出版结果都返回到了大数据中心,大数据中心的数据为我们新的图书出版提供服务。这是我们从图书出版回到图书出版的过程。为了实现这一过程,我们自己开发了很多技术工具,包括以数年来的海量数据为基础,利用机器学习来实现的自动标点、OCR识别等。我们的技术工具一方面为编辑出版服务,同时也为用户服务。流程图左上角是作者,随着在线整理平台的建立,作者为我们提供内容,我们为作者提供数据和技术服务,帮助作者整理、校对。
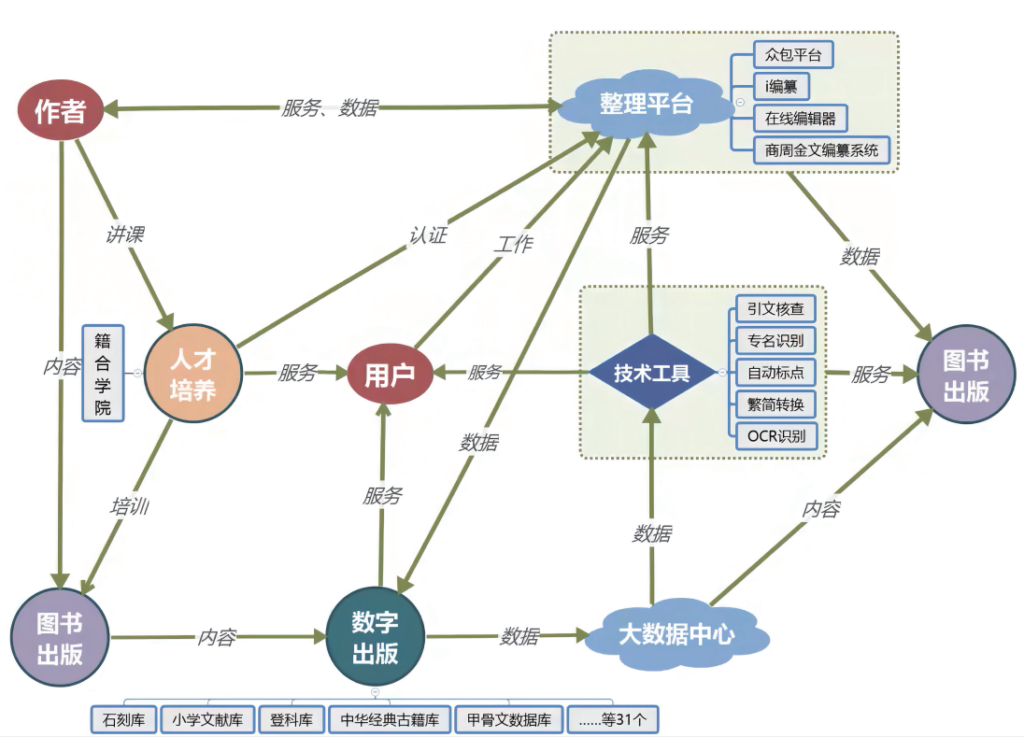
图1 籍合网业务流程图
随着在线古籍整理工作平台任务的增加(我们已经处理了十几亿字),需要大量的古籍数字化整理的人才。因此,我们就逐步建立起人才培养机制,也就是最近上线的籍合学院。图中左上角的作者同时也是人才培养的老师,他能够向读者讲授古籍如何整理。我们培养的人才既有出版社的编辑,也有参与在线众包工作的人员。通过认证后,所有人都可以在线提供编校服务。这些都是我们参与到古籍整理课程学习的用户。这样一种机制让古籍整理平台不仅仅是一个软件或一个系统,而是一整套的商业模式和服务。大家看到的籍合网就是这套商业模式的前台,当然后台还有很多工作在配合。
作为企业,我们对于古籍数字化平台的概念和理解,可能和学者所思考的平台工作稍微有一些差异。所有智能化的、知识化的工具技术,都是根据我们业务模式的需要来研发的。下面我再对这个业务模式涉及的内容做一些补充说明。籍合网目前涵盖数据库产品三十多个,分成了不同的门类。古联公司的基因整体来说还是出版社的基因,所以我们在建立内容服务时也是按照出版社的要求,首要考虑资源的整理属性,考虑出版质量,其次才是附加功能和智能化服务。
有了这些数据库,下一步我们就考虑如何为出版社服务,所以建立了一个在线编纂的众包平台。应该说它是古籍整理领域建立的最早的众包平台,也是规模最大的平台。最初整理工作平台上就有3,000多个整理者,随后,为了拥抱移动互联网,我们发布了一个移动端的微信小程序——i编纂,将用户扩展到5,000人。读者可以在这个小程序里申领任务,随时接收我们发布的任务信息,领到任务之后,利用在线编辑器完成工作。为了满足不同的工作需要,我们建立了不同类型的在线编辑器,有的是编辑数据库的,有的是编辑书稿的,满足不同的格式要求。随着需要处理的数据量逐步增大,我们开始觉得需要更多的技术力量给予支持。深度学习技术不断发展,我们发现它能为古籍整理自动化提供很多的帮助。因此,我们建立了自己的大数据中心,开展数据模型训练,服务于自动标点、文白翻译、繁简转换,还有OCR等业务。
近年来我们开发的古籍编辑智能化工具更重视为现阶段古籍整理本身服务,所以开发了如自动标点、繁简转换、OCR识别及引文核查等工具,我们的关注点在于提高了多少编辑生产效率。大概于2013年,我们也做过类似知识图谱、本体建模的项目,包括我们和武汉大学董慧老师合作的大型的基于本体的“二十四史”知识系统,但暂时没有在这个领域走向产品化。虽然目前商业用途和学术服务还是有一些差距的,但这是我们面向知识服务要去考虑的问题。
我们为编辑做过“文达”编校系统,可以在word中作为插件来使用,进行专名、繁简等编辑内容的检查,以及古籍引文的核对,提升了编辑工作的效率。面向整理者的,融合各种工具的在线古籍整理平台也即将上线。
我们需根据古籍整理数字化工作业务流程进行开发,最开始需要对图像进行OCR识别,之后整合已有的众包平台开展校对,使用自动标点、繁简转换工具加速整理。再比如,针对有些繁体或简体横排的古籍,我们设计了不同版本的自动标点工具。很多处理细节都体现了我们的实际业务和学术关注点的不同之处。在数字化整理后的文本内容进入纸书出版环节时,我们还有一个将XML文件向排版文件转化的系统。可以说我们的智能化服务是围绕古籍整理数字化工作流程展开并逐步发展起来的。
图2 “籍合学院古籍整理训练平台”首页(局部)
最后,谈谈去年建立的古籍整理培训平台——籍合学院(图2)。其实我们很早就想做这件事,最初是想做线下培训,因为发生疫情就把培训挪到了线上,建立了这个平台。籍合学院的理念就是讲授古籍整理相关实践内容。我们和学校不同,如北京大学的中国古典文献学专业可能对于理论知识、基础学科知识的传授是非常充分的,作为企业服务达不到这样的程度。因此,我们更多的是案例课、技能课。我们请老师来讲一本古籍是如何整理的,如何选择底本的,如何解决具体问题,等等,然后把教学和古籍数字整理生态环境搭配在一起。用户可以到众包整理平台进行训练,完成任务。完成课程学习并考核通过的学员,将获得由中华书局颁发的电子结业证书。我们和很多学校共建了教学实习实训的基地,学生也可以参与到我们相关的实践工作当中来,参与我们数据库和纸书的整理和编辑。这样,我们就逐步打造了一个从学习到实践的教学的环境,既为学校人才培养提供服务,也培养了我们自己的编辑力量,储备了企业的人才。因此,籍合学院构成了古籍数字化平台新的一环。
朱厚权(元引科技有限公司):人文数据类学术成果转化探索与实践——以引得CBDB平台为例
我从一个纯商业的角度,对我们在数字人文及相关平台建设方面进行的探索做简单梳理,请各位方家批评指正。
这个题目其实是从引得CBDB项目来展开的。引得CBDB,也即CBDB项目本身,和我们中国有很深的历史渊源。CBDB(“中国历代人物传记资料库”)是1970年代郝若贝(Robert M. Hartwell)先生基于个人研究需要所开发的一个数据平台。在他去世以后,2005年CBDB被正式遗赠给哈佛大学。在CBDB整个项目的开发过程中,对很多数据及模式进行了不断的探索和尝试。它整体的延续形态和中国大陆的社会科学基金资助方式是类似的,相较于中国大陆的团队,它的项目募资能力可能要更强一些,主动性也更强一些,对科研成果开展商业化转化的态度更开放一些。从中文在线集团的角度来讲,和CBDB结缘本质上是和我们企业的使命完全分不开的。中文在线集团是2000年由童之磊先生清华大学在读时创立的一家企业,一直以来,企业的使命就定义为“数字传承文明”,直到现在我们一直坚持着这个使命,并且在不断地实践、深化。2015年公司在深交所正式上市以后,童之磊先生对于企业使命有了更深层次的理解。他认为,经过十五年的探索,我们的“数字传承文明”传承和实践的更多是近现代文明,所包涵的“文明”还有所欠缺。因此,我们需要不断创新,以“10年+”的心态,以未来的视角来突破现在的边界。于是,2016年童之磊先生赴哈佛大学访学,期间,他和费正清中国研究中心的包弼德老师及其他学者们展开了深层次的研讨,深刻地感受到业界所流传的那句话——“汉学在国内,但是汉学传播及汉学研究的高峰在国外”,同时也深深地被“中国历代人物传记资料库”即CBDB项目小组几十年如一日地研究汉学,对汉学相关数据持之以恒的追求精神所感动。在他正式访学结束之前,也就是2018年,在上海哈佛中心,中文在线、哈佛大学、北京大学与台湾“中研院”四方正式签约合作。我们从商业角度,希望CBDB这个优秀的学术产品在更多领域有更深层次的实践。在签约现场,包弼德老师提出,希望在中国大陆地区建设基于中国研究的网络基础设施。为此,我们进行了不懈地努力。
2018年至今,四年多的合作过程中,我们取得了一些成果。CBDB学术委员会带领团队不断创新。
在传主数据方面,从2018年的37万增长到2021年的51万多,足足增长了近15万。从这个角度来看,商业力量的介入对数据建设速度贡献了显著力量,两相对比,原来纯基金资助或者是纯个人意愿推动的方式不可同日而语。另一方面,对于相关的方法论,我们也有了更多、更深入的探索和实践,也产出了更多的研究成果。
当然,在合作伙伴方面,我们也有了一些更深层次的合作,比如除了把CBDB正式引入中国,并且进行相关商业化探索以外,我们将荷兰莱顿大学魏希德老师主持的MARKUS产品的商业化产权也进行买断,进行更多的探索。当然,在商业化的探索中也发现,基于集团体系的KPI和OKR考核,对建设周期相对较长的文化产品十分不利,再优秀的文化产品也很难在短期内实现真正盘活,以达到集团管控的生存线。这一方式和洪涛总经理之前在中华书局负责一个部门但后来独立运营大获成功的逻辑本质其实是相通的,所以在种方式下,我们从传主数据、学术委员引进、合作模式探索、孵化数字人文业务公司等方面都进行了深度拓展和尝试,希望能为相关参与团队有所借鉴。
其实经过这四年多的探索,我们对学术及学术产品有了更深入、更广泛的接触,也有了更广的接受度,产品也在不断地更新迭代。对于当前的数字人文业态来说,我们也发现它在不断地快速演进。在网络环境下或数字场景下,大家首先想到的方法就是图像化和文本化可以帮助人文学者将传统方式方法和研究范式向计算机辅助研究快速迁移,古籍图像化和文本化相比传统方法,在效率上有了显著的提升,应用也更为广泛,技术成熟度也更高,它可以帮助学者轻松实现相关的检索、分析和对比,大大减轻人文学者处理基础数据和资料的工作量。有了这些数字人文领域里的基础设施和理念共识,就可以进行更多的功能探索。
第二类方法涉及本体化、结构化和图谱化方向。近年来,我在和各位老师的沟通过程中发现,第二类方法多被理解成舶来品,是对传统方式方法的一种增强或者拓展,这种方式方法涉及很多的大尺度统计、聚类以及量化、可视化,需要一系列的辅助工具。工具多了,本质上就构成了一个相关的平台,直至最后就形成一个生态系统。
经过多年的探索,我们对于当前的数字人文平台或网络基础设施方面有了一些更深层次的感受,希望借此提炼出数字人文教学研究和训练领域里基本的、刚需的构件。首先是涉及相关领域本体或领域词表的构建,这是整个数字平台的核心构件、核心基础之一。有了这个基础之后,我们就可以建设相关资料库、数据库等。有了资料库和数据库,我们就可以将数据关联的难度显著降低。最后,形成可关联的一个平台、一个体系。基于这些资源,我们在教学和研究的过程当中,也需要相关的研究工具及教学工具来辅助进行教学研究和探索。
在此基础上,我们可以把应用工具做简单的分类——基本上可以把应用工具分成四大类:第一类是文本处理方向的一系列工具,包括文本识别、自动句读、专名识别、不同学科专名标注、学科分词、文本比对、相似句比对、文本复用等一系列处理工具套件。在文本处理基础上,需要的是第二类的文本分析工具,比如我们可以做相关文本不同风格的计算——不同作者的风格,同一个作者早、中、晚期的风格,以及不同作品之间的风格计算,还有情感计量、关系获取等其他方向的探索。这个领域需要非常多的工具套件,根据不同的研究需求,我们目前已经开发出了一系列组件。但它们都有一定的研究适用范围,比如我们当前主要服务计算语言学或者诗歌研究,当我们服务于医学或农学时,可能就需要新定制一些相关算法模型。从本质上讲,各类工具前端交互和后端有很多共通点,可能只是在模型方面有所差异而已。
第三类是在文本处理及文本分析基础上,学者可能需要更多地在视觉上进行呈现,让展示和交流能够无障碍,那么就需要社会网络分析、历史地理分析、语义网络、词云、文字云等一系列展示工具。由此,我们开发了相关的可视化套件,利于学者进行探索。我们公司在众包方面也做了一些更深层次的、基于产业方面的探索。这样的重磅工具,可以改变原来由一位教授领导一个团队单兵作业的状态,使得基于团队的协同作业可以更好地服务于未来的数字人文研究。在这种场景下,我们就可以随时随地向社会面发布招募任务,并且能够有效避免出现原来流水线式作业中因某一个人延期而导致的整个任务档期延宕。同时,我们希望将来构建的平台是开放的,各个方面都能进行API对接,能帮助各个平台打通信息孤岛。
经过几年的探索,我们和清华大学人文学院共同做了一些基础的尝试,比如我们面向清华大学人文学院数字人文教学需要,共同开发了文本功能平台。针对不同的数据,不同的学者可以根据自己的需求进行不同的渲染,可以下载原始数据,也可以利用平台进行深度的综合利用。该平台还有很多其他功能的展示,如文本处理模块包含学科标注、自动句读、命名实体、简繁转换及文本分词;文本分析模块包含风格计算、情感计量、主题模型等相关尝试;视觉呈现模块包含历史地理及社会网络分析;研究资源既包括一些传统古籍文献,也包括不同学科不同学者建设的相关语料。
关于结构化文本,我向大家介绍一个相关案例。以《红楼梦》为例,传统的教学过程中应用的是纯文本内容,在对文本进行结构化的过程中,如果同学们对统计及相关探索有需求,需要对整个文本里的情绪、植物、食物、服饰等进行相关研究,就可以利用文本功能平台里的学科标注工具或者命名实体提取工具,快速将《红楼梦》相关实体提取出来。清华大学程宁博士也做了相关研究——分析林黛玉和薛宝钗的说话风格,这就需要把文本中林黛玉和薛宝钗说的话汲取出来,进而分析、发现她们二人说话的风格差异。如果按照传统的方式方法,摘录二人说话可能需要一条一条地复制粘贴,但是基于现在的方式,效率就会相对提高很多。
下面介绍一下我们对于学术成果转化的一些探索和相关思考。首先,学术研究的独创性和工程实践的可复制性之间冲突比较明显。当然它们也是相辅相成的——具备了学术研究的独创性,经过市场检验,我们可以把它发展成一个完整的产品。但是它们之间仍有着不可调和的矛盾,主要分三方面。
第一,学术的独创性与工程实践的批量化冲突。学术研究讲究标新立异,讲究开宗立派,讲究创立一门学科、一个方法论,要体现出学术的独创性。但是工程或者大众市场需要的是可批量复制的商品,因为复制以后才可能有利润,才有可能创造更多符合需要的商品。这时怎样才能保证独创性、科学性并批量化制造?我们基于CBDB进行了一些尝试,比如群体传记研究从提出到现在还是有很多学者对其持批评态度,但是经过多年持续地开展工作坊、组织暑期学校,国内越来越多的学者慢慢地开始接受这种方法论的实践。这既维持了学术的独创性,对于产品推广也是相对有好处的。
第二,学术版公益承诺与商业化版本的趋利冲突。众所周知,CBDB在商业化之前有一个免费的单机版ACCESS程序,是当时对美国的国会基金会、我国台湾的蒋经国基金会以及香港的唐研究基金会等要求CBDB开放获取的产物。但是这些资助都是有一定期限的,如果在这个期限之内不能引入新的、有活力的长期资金,这个项目就可能戛然而止。那么这时如果项目能进行相关的科研成果转化,进行商业化,就需要对公益承诺和商业化版本的矛盾有一定解决方案。目前我们的处理方式是,CBDB公益承诺和商业化版本的数据逐步有越来越多的差异。首先,商业化版本数据更新、更快,每天都有更新。另外,商业化版本面向更多实践,如CBDB本身更侧重于社会交往关系,那么我们探索的将来的商业化版本可能在正史、地方志方向建设更多数据,以方便更多学者引用。此外,在商业化推广时,如果我们面向图书馆开放在线系统,那么很多人就可以在图书馆系统实时在线检索。比如,检索某一个名人,CBDB的数据看上去和我们通常了解的信息差异很大,这时我们会根据需要来重点补充该名人的重点事迹、行迹、事件等。这些是在原来纯学术版本中不会考虑的。
第三,学术的代际创新与工程类微创新的冲突。这两者之间必须有一个桥梁来融合——数字化、文本化到结构化、可视化其实跨度是很大的,尤其是像包弼德教授团队一直在推广的结构化数据与我们原来的文白对照、传统出版及数字出版之间的跨越难度,比原来的融合创新要更大。在这个方面,如果没有建设桥梁,那么结构化数据到产品推广及商业化复制是存在很大鸿沟的。比如,很多学者对CBDB数据的出处有所质疑,那怎么样来回答这种质疑?我们需要构建面向整个历代文献出处的文献库,帮助学者不再跨越多个平台、频繁登录多个网址,来确认这条信息的正确性或科学性。
当然,对于学者的平台开发和伙伴选择方面,我们也有一定的体悟。有好几个学者研发了相关产品并与我们讨论过,比如,想选择一个比较大的合作伙伴是否更合适更安全?主营的方向不同可否合作?我们总结认为,合作伙伴的体量很重要但不是最重要的。一个非常明显的例子——如果这个合作伙伴的销售额体量是十亿、百亿甚至千亿级别,众所周知,面向人文领域的产品最终的销售额可能也就几十或上百万,整个销售额体量能到几千万或者上亿,那就已经是一家很不错的公司。如果一个小产品一年的销售只有几十万、几百万,那么严格来说,大型的合作伙伴是不太会瞧得上的。另外一方面,人文产品的推广难度和面向C端产品的推广难度完全不可同日而语。在经营方向上,如果选择了一个大体量的公司,并且经营方向不是人文领域的,那这于该公司来说可能就是一项慈善事业或者捐赠,这对于我们原来合作的初衷、我们的使命或价值观是一个致命打击。
另外,也有很多学者咨询过我们,应该怎么选择技术路线?是选用最新的技术还是相对成熟的技术为好?我们认为,只要适用就好。比如,针对当前较流行的图数据库技术,有很多人问过我,CBDB本身是一个结构化的数据,为什么不选用图数据库?其实这是由几个方面来决定的:第一,最新的技术不见得是最适用的技术。第二,很多的图数据库是要高额收费的,如果在当时情况下或是在多年之内不能为高额的数据库使用费买单,那即使再好的技术也是一种不适用的技术。此外,一些学者和我们探讨过科研成果的输出问题。面对非常好的作品,我们希望能复制、形成规模。但好的成果是不是经得起工程检验,或者市场检验、用户检验,是无法保证的。只有通过了这些检验的产品,相对来说才是实用的、能活下去的产品,到最后“剩”下来的产品才是一个好的产品。最后,一些学者向我们询问产品能不能和其他合作伙伴一起形成集聚效应?集聚效应有没有促进自身产品获得更好的利益?面对这个问题,我的感受是——如果您的产品跟您选择的合作伙伴的产品之间有一些共鸣,那么本质上是更好的。相对来说,一个单体产品在规模不大的情况下很难商业化,如果进行商业化,也较难取得长久的运营效果。
整理:丁卓源/中山大学中文系
朱坤豪/郑州大学信息管理学院
白翔宇/山东大学历史文化学院
(编辑:徐璇)
注释:
[1]网址为:https://www.allhistory.com/。
[2]刘石、尹小林:《以数字映射古代文学经典》,《光明日报》,2022年3月23日,第11版。
[3]王兆鹏:《大数据里的唐宋诗词世界》,《光明日报》,2022年3月23日,第11版。