您正在访问旧版存档页面。This is the old version archive of our site.

科幻与推理小说中的解谜叙事 ——基于词频动力学的远读与可视化研究
整合单个词汇的一维词频分布链,通过优化关联系数,可以得到一个反映文本叙事结构的二维图像。以《三体2》和《东方快车谋杀案》为范例……
作者:刘洋,转自:公众号 DH数字人文

刘 洋 / 南方科技大学人文社科学院
————————————————————-
摘 要:整合单个词汇的一维词频分布链,通过优化关联系数,可以得到一个反映文本叙事结构的二维图像。以《三体2》和《东方快车谋杀案》为范例,通过对其关联词频时序图的分析,可以直观地观察到叙事主线、逻辑推演、故事高潮、解谜收束等结构性特征。在词频集聚函数的图像上,高潮与解谜阶段均出现了特定的峰值。对大量文本的平均词频集聚函数进行分析后发现,解谜峰在推理小说组别的图像上是一个最为显著的特征,表明解谜型叙事在推理小说的创作中被广泛使用。这种基于词频动力学分析的方法是一种有效的对叙事文本的远读和可视化方案。
关键词:叙事结构 词频动力学 解谜叙事 远读 可视化
————————————————————-
引 言
在各种虚构性叙事文本中,为了增加故事的张力,维持读者的阅读兴趣,作家通常会在叙事过程中引入一些悬念,通过具有逻辑性的推演,在文本的结尾处对其做出解释。这种叙事结构早先形成于侦探推理小说中,这是由于其文类本身的特点所决定的。Freeman曾将侦探推理小说的叙事分为四个阶段:提出问题、展示数据、了解真相、验证结局。[1]这种叙事方式已经形成了一种成熟的写作套路,不妨将其概括为“解谜式”的叙事结构。随着推理小说的发展,其解谜的目标也从最初的犯罪凶手逐渐扩大到其他的要素,比如某种出人意料的犯罪手法,或凶手的犯罪动机等。其实,解谜式叙事并不是推理小说所特有的,在众多文学作品中都可以看到类似的叙事结构,只不过解谜的目标不同罢了。在科幻小说里,这个谜底通常和作者的核心设定紧密相关,例如关于某场巨大灾难的起因、某个奇观的物理机制、某种外星生物的意图,乃至整个宇宙的真实构造。
本文拟对这一广泛应用的叙事结构进行一个跨作家、作品,乃至跨文类的分析研究,并提供一种对作品叙事结构可视化呈现的途径。传统上,对各类文本叙事结构的研究多属于阐释型研究,而且主要针对单一作家或单一作品进行。[2]近年来,开始出现一些对文本结构的实证性研究,其本质是对文本中的隐藏模式进行挖掘。例如,Don等人开发了一个名为FeatureLens的图形界面工具,对不同类型的文本进行了模式挖掘和可视化的尝试。[3]张旋等人在复杂网络分析的基础上,对14部金庸武侠小说中主角的爱情模式进行了挖掘,构建了一个具有较高精准度的识别框架。[4]胡启月等人借助自相似分形理论中的Hurst指数对哈利波特系列电影的台词进行了情感时间序列的研究,发现其一定程度上可以反映出故事情节的走向。[5]他们也用类似的方法来分析了石黑一雄小说《永不放手》中的叙事连贯性和情感的动态演变,[6]以及丹麦牧师Grundtvig的整个创作生涯的发展轨迹。[7]具体到对叙事模式的挖掘,目前的研究仍然很少。Snelgrove借助于一个结构分析程序分析了一些文本的叙事结构,但依赖于人工插入文本中的标签。[8]Hess等对修昔底德作品中的叙事模式进行了分析,基于叙述者和人物角色在语言上的区别,但这种方式并不具有普适性。[9]
在本文中,我们提出了一种基于词频动力学的叙事结构挖掘与可视化方案。该方案借助于关联词频时序图,可以呈现出众多关键词词频在文本分区序列中的变化情况,因此不同于一般的全局性的、静态的统计方式,是一种在文本时序坐标上动态(dynamic)呈现的数据序列。从关联词频时序图中,我们可以直观地观察到叙事主线、逻辑推演、故事高潮、解谜收束等结构性特征。同时,为了进行跨文本和跨文类的比较,我们还构建了词频集聚函数这一量化指标,用以表征若干关键词汇在叙事时序轴上的聚合程度。研究发现,这一函数在时序轴上的峰值,可以指示出文本中解谜叙事的集中推理区,因此是我们研究不同文本解谜叙事模式的一种有力工具。
一、关联词频时序图的构建
为了构建一个动态的词频序列,我们需要将文本按照先后顺序划分成不同的区块,然后分块进行词频统计。据此我们可以得到特定词汇在文本中的分布图,如图1所示。图中,我们以阿加莎·克里斯蒂的著名侦探小说《东方快车谋杀案》为源文本,对“列车”“凶手”“睡衣”三个词进行了词频统计,得到了它们在不同文本块中出现的次数。左侧与右侧的三个子图,是在不同分块粒度的情况下提取的数据,分别将全文分为了420个和140个区块。从中可以看到,粒度越小,图像越精细,但考虑到可视化与计算消耗,也并非是粒度越小越好。
另外,每个文本序列的词汇数并非完全相等。为了尽量不对源文本产生割裂,我们采用了一种弹性分块的方式:设定区块的词汇量为N±s,也就是在[N-s,N+s]的文本范围内,寻找最接近N的自然分段。若范围内没有自然分段,则在词汇N处进行分块。在本文的研究中,N一般取150,s取30。
接下来,我们将不同词语的时序图按照文本序列对齐的方式横向拼接在一起。我们希望通过拼接出的图像直观地得到有关叙事结构的信息。因此,参与拼接的词汇应该是那些能够反映作品核心内容的关键词。我们首先通过停用词表去除无意义的符号、连接词或较平庸的功能词。之后,我们需要通过特定算法从文本中提取与故事相关性最强的一批关键词。我们尝试了TF-IDF(term frequency–inverse document frequency)算法[9]和TextRank算法[10],结果表明前者具有更好的效果,但仍然会提取出少量与故事无关的词汇,或者漏掉关键性的词汇。由于与故事关联更强的词汇通常是名词,因此我们在TF-IDF算法中加入了不同词性的权重因子,也即:
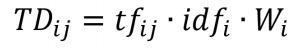
其中tfij是词汇i在文本j中的词频(Term Frequency),idfi是词汇i的逆文件频率(Inverse Document Frequency),Wi则是词汇i的词性权重。我们设置名词的权重为2,动词权重为1.5,其余词性的权重均为1。
通过这种加权的TF-IDF算法,可以较好地提取出我们所需要的关键词。在研究中,一般将TDij值最大的40至60个关键词提取出来,作为参与拼接的词汇。这一量级的关键词数目已经足以囊括与故事主体相关的词汇。
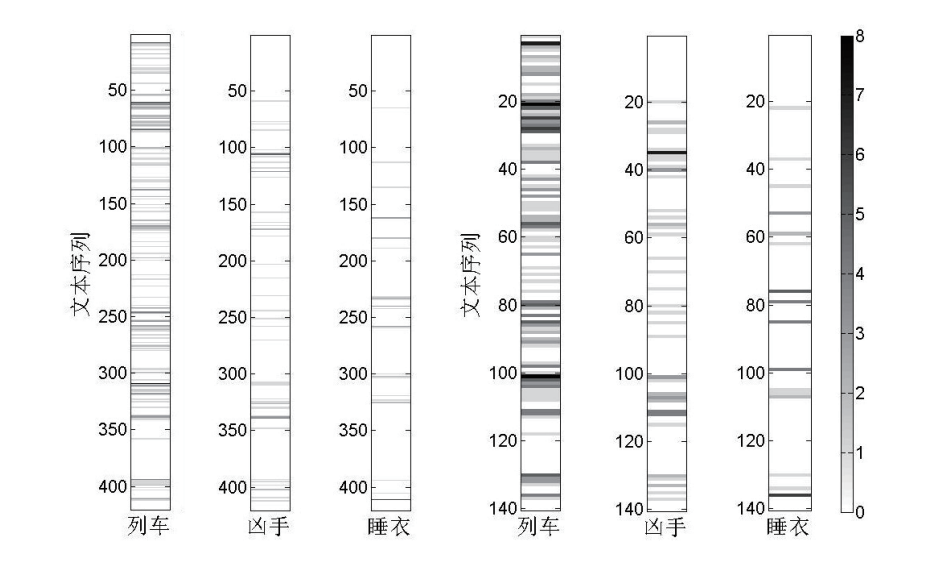
文本源为《东方快车谋杀案》,图中所示为“列车”“凶手”“睡衣”三词在文本序列中的词频及其分布。左右各三个子图的划分粒度不同,纵轴为文本序列编号,所有子图共享最右的颜色栏。颜色越深,表明该文本块部分的词频越高。
在确定了入选的关键词后,我们接下来尝试将所有词汇的时序图拼接在一起,从而把一维的时序图扩展为一个二维的图像。这时,最重要的问题就是确定一个合理的拼接顺序,让得到的二维图像能够直观地呈现出文本的叙事结构。我们认为,叙事结构在文本中体现为各关键词的词频在不同文本块中的动态变化规律。叙事推进的过程,就是各关键词随着文本进度而相继出现高频峰的过程。因此,在相近的文本块中出现高频峰的词汇,或者更直接地说,在同一个文本块中同时出现的高频词汇,在叙事中一定具有较强的关联性。所以,在确定拼接顺序的时候,将那些共现或出现位置接近的词汇尽量排列在一起,是我们应该遵循的核心原则。
为了找出这样的一个最优的排序方式,我们对于每个排序都定义一个对应的关联系数C,以表征在这种排序方式下,系统在整体上的关联程度的高低:
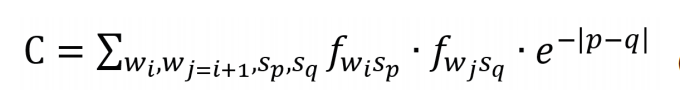
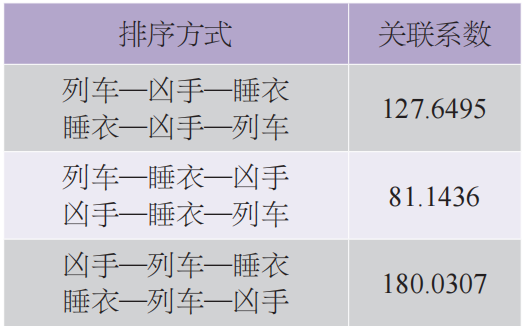
其中i、j是对排序后的词汇的编号,p、q是对文本序列的编号,fwisp为词汇wi在序列sp中的词频。e指数是为了量化词汇间的位置距离与彼此的关联性——在时序轴上的距离越远(|p-q|越大),关联越小。当两个词汇处于同一时序中,即p=q时,也就是通常所说的共现状态,这种情况意味着两个词汇在文本中具有最大的关联性。例如,在图1所示的《东方快车谋杀案》的文本中,我们如果选择列车、凶手、睡衣三个词汇进行分析,在“列车—凶手—睡衣”这一排序下,三个词汇的编号分别为w1、w2、w3,而整个文本根据左侧的粒度被分为420个时间序列,即s1至s420。根据公式2,这种排序方式对应的关联系数的计算方式为:

在不同的词汇排列方式中,我们应该选择让关联系数C最大化的排序方式,这样才可以在最终的二维图像中最大化地呈现出词汇间的关联性。以上式为例,计算结果为127.6495。但如果我们改变三个词汇的排列顺序,计算所得的关联系数也就发生了相应的改变。各种词汇的排列方式及其关联系数如表1所示。注意,a-b-c与c-b-a两种词汇排序的方式,只是相当于对拼接后的图像进行了轴对称变换,所以它们实际上是等价的排列方式,其关联系数是一样的。
从表1可知,第三种排序方式对应的关联系数最大,所以在进行时序图拼接时应该按照这样的方式排列不同词汇的顺序。在进行实际研究时,我们选取的词汇量当然远不止3个,其排列方式也非常多。寻找最优排列的计算量随词汇量的增大而显著增加,我们一般选取50个左右的关键词,这样可以在文本叙事结构的完整呈现和计算资源的消耗上取得较好的平衡。然而,如果通过遍历的方式计算出所有词汇排序方式所对应的关联系数,计算量将极为巨大,因此,我们设计了一种依序堆叠的算法,极大地减少了所需的计算量。可以证明,这种“堆叠算法”的排序结果在只考虑共现关联时,即C=Σwi,wj=i+1,spfwisp·fwisp时,其与遍历算法所得到的结果是一致的。在附录中,我们对这一结论给出了详细的证明。而由于e指数随着时序差值的迅速衰减性,在大部分情况下,共现关联占据了总关联数值的绝大部分。因此,即便在考虑了所有关联项的一般情况下,这种堆叠算法也可以很好地逼近遍历算法的结果。事实上,在词汇量较少的情况下(不超过6个),我们比较了堆叠算法和遍历算法的排序,两者得到的结果是一样的。
表 1 不同排序下的关联系数示例
按照最优排序拼接出的“关联词频时序图”(Correlated Word-frequency Sequence, CWS),相邻词汇间的词频序列具有最大的共现性,因此可以帮助我们分析文本的叙事结构。例如,我们对刘慈欣所著科幻作品《三体2》进行了关联词频时序图的绘制,如图2左侧所示。为了更清楚地看到图中展示的叙事脉络,我们可以将其中数值较高的点标记为热点,并且将距离较近的热点用直线连接起来,以便突出它们之间在文本中的关联。在本文中,热点的词频下限一般是3,连线的距离上限H一般是10,其定义为:
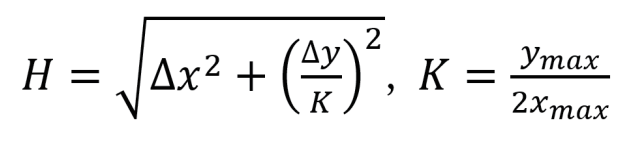
其中∆x是两个热点的横轴数值差,∆y是两个热点的纵轴数值之差。考虑到文本序列的数量显著大于词汇的数量,因此对纵轴距离进行了压缩处理,压缩参数K的取值为纵轴最大值除以两倍的横轴最大值。通过这样的处理,等效于将原图缩放为了一个纵轴长度为横轴两倍的长方形区域,与实际看到的图像更为接近。图2右侧就是通过这种方式得到的热点网络图。与左侧相比,它更为清晰地展示了文本的叙事结构。
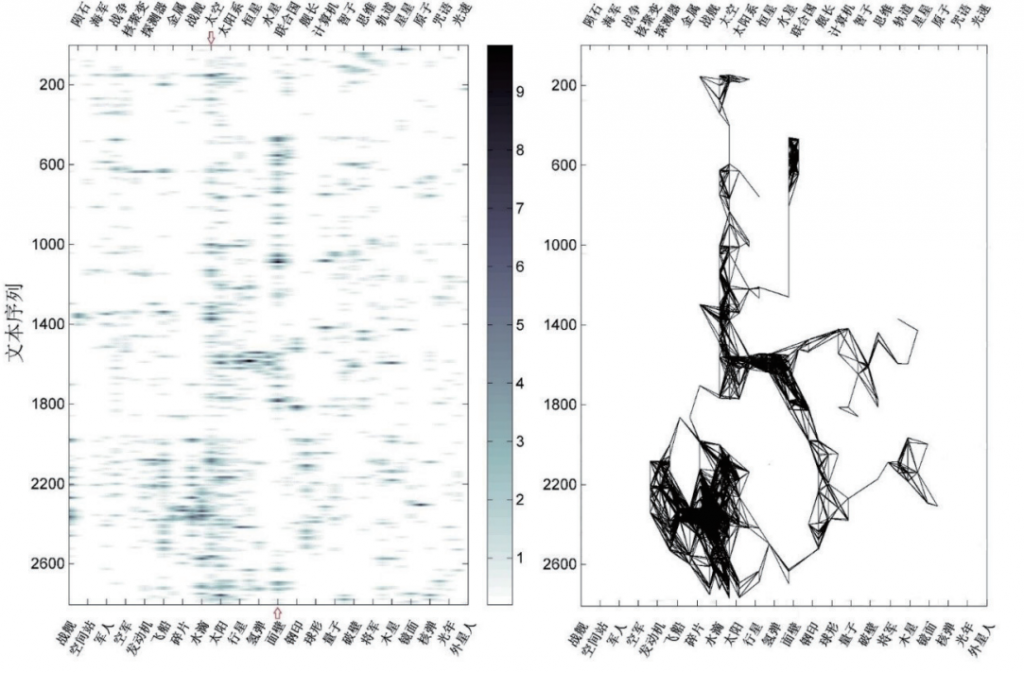
左图的纵轴为文本序列,横轴为不同的词汇。为了便于察看,图中将所有词汇分为两组分别显示在边框的上下两侧,位置对应于该词排序的编号。注意,上、下横轴的坐标位置是间隔排列的。右图则是将左图中数值较大、距离较近的点用直线连接后形成的热点网络图。
二、基于词频动力学的叙事结构分析
接下来,我们以《三体2》与《东方快车谋杀案》为例,通过分析其关联词频时序图,挖掘隐藏在其中的解谜式叙事的结构特征。前者是当代著名的科幻小说,后者是经典的侦探推理小说,然而在叙事模式上,它们都具有类似的结构。在最后,我们将引入一个包括科幻与推理两组小说的语料库,针对解谜型叙事的特征,进行一个跨文本、跨文类的分析比较。
1.主线
小说的主线一般具有两个特征,一是贯穿故事的始终,二是在文本中频繁出现。因此,在关联词频时序图中,主线一般表现为一条较为连贯的纵向的深色线区。从图2的左图中,我们可以明显地看到两条贯穿全文的主线,其一以“太空”为主轴,其二以“面壁”为主轴。[11]《三体2》具有一个典型的科幻小说的主题:人类面临某种全球性的危机,某个英雄人物拯救了地球。具体来说,危机来自于三体舰队,来自神秘的太空,而解决危机的方法则是所谓的“面壁计划”。因此“太空”和“面壁”分别对应了故事的两个关键点,即人类危机的源头与对策。
根据图2,我们可以把《三体2》的整个叙事文本分为5个部分。在400节[12]之前是第1部分,以太空主线为主,叙述危机的来由。400节到1200节为第2部分,“面壁”占据了明显的主导地位,形成了一条清晰而浓重的竖线。这部分内容主要是呈现各个面壁者与破壁者之间的交锋,渲染绝望的情绪,为最后的面壁者罗辑做好铺垫。1200节到1900节为第3部分,其主要特征为图中出现了一个“K”字型结构,两条主线间出现了直接交互。第4部分是1900节到2600节,水滴、战舰、探测器、飞船、碎片等词汇集中出现,形成一个密集的团簇,故事进入到高潮阶段:水滴摧毁人类舰队。2600节之后是故事的结局,谜底揭晓。图像向着“太阳”的位置有一个明显地收束效应——事实上矛盾的解决方案确实与太阳紧密相关。
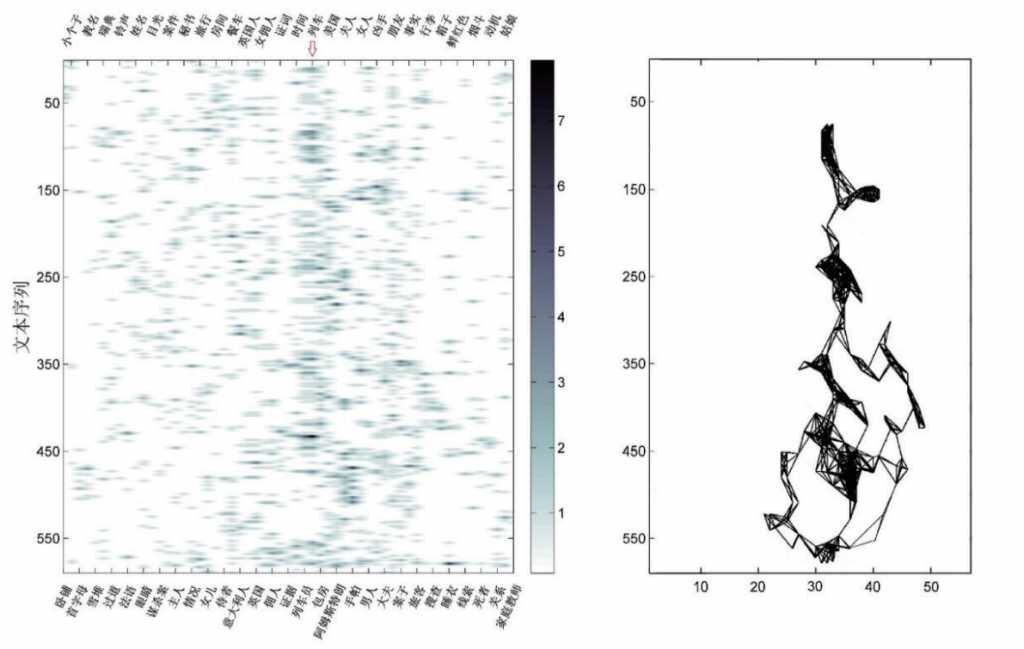
由于横轴对应的词语较多,故在右图中不再重复标注,以词汇在左图中的排序编号代替,即数字1对应“卧铺”,数字2对应“小个子”,依次类推。
图3左侧为《东方快车谋杀案》的关联词频时序图。从中可以看到,在450节之前,“列车”是当之无愧的主线,它是故事发生的场所,也是推理的依据和线索。与《三体2》相比,该文前期的关键词较为分散,在图中可以看到众多细微的局部结构,体现出侦探推理小说的一大特点:在谜团构建时呈现出数量繁多而纷乱的线索。在450到510节之间,“手帕”短暂地成为了叙事主线,显示这一阶段推理的关键线索集中在了手帕这一物件之上。510节之后,线索开始收束,“阿姆斯特朗”一词是最主要的收束点——这正是解开凶案迷局的关键线索。
在图2和图3右侧的热点网络图中,同样可以清楚地看到主线的特征。在图2的“太空”“面壁”二词和图3的“列车”一词所对应的纵向位置,都可以看到密集分布的直线簇。这些直线簇围绕竖直方向交错纠缠在一起,与左侧关联词频时序图中的深色渲染区域形成对应,但因为直线的连接填补了孤点之间的空白区域,因此在对故事主线的呈现上显得更为直观。
2.推演
这里的推演,指的是叙事线索随文本序列的推进和演化。它反映了作品在故事构造和叙事中的逻辑性,也是其推想性和创造性的重要体现。在解谜叙事型作品中,推演是必不可少的组成部分,是解谜的前提。在关联词频时序图中,其呈现为一条倾斜的深色线区,延伸方向以朝向主线为主,特别是在作品的后期。
我们以《东方快车谋杀案》第一部第七章为例,说明推演型叙事在关联词频时序图中的构型。该部分内容在文本序列中的编号大致位于140节到180节之间,我们将相关部分单独绘制出来,如图4所示。图中用条形胶囊标记的区域,就是一个典型的推演型叙事的构型。按照文本时序的先后,其涉及到的词汇依次有朋友、大夫、凶手、男人、女人、手帕、夫人、阿姆斯特朗、美国。
通过文本细读,我们可以理清这次推演过程的具体逻辑:侦探波洛应“朋友”布克之邀,参加了凶案的调查;首先,“大夫”查验了死者的尸体,初步推测“凶手”应该是一个“男人”,因为几处伤口需要很大的力气才能造成;但波洛根据伤口数量和分布推测,凶手更像是个“女人”;他在地上发现了一块女式“手帕”,似乎印证了自己的判断;接着,借助从一位“夫人”那里拿到的铁丝网,他看清了烧焦纸片上的残留字迹——“阿姆斯特朗”,从而想起了一起发生在“美国”的绑架案,明白了死者的真实身份。可以看到,从查验尸体开始,一直到推测出死者的身份,这正是一个典型的推演过程。通过提取文本中的关键词汇,绘制出关联词频时序图,可以直观地将这类推演过程以独特的构型呈现出来。
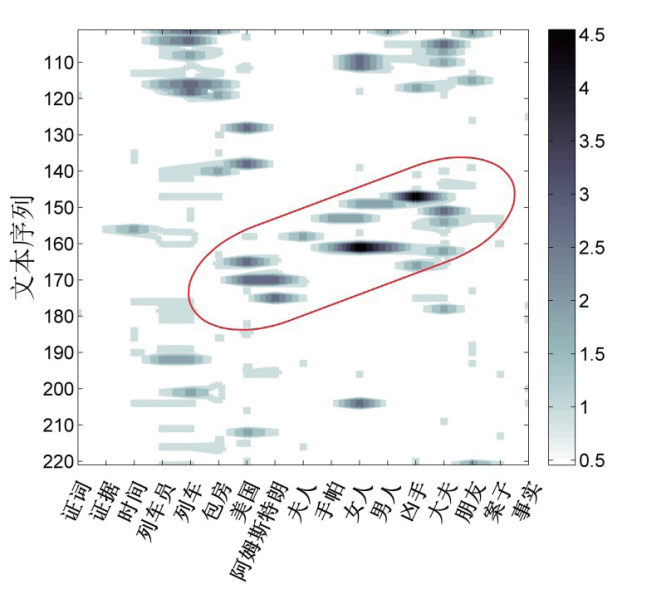
我们注意到,这种推演构型会产生一个斜向的热点群区域,因此它在热点网络图中会得到更直观的呈现。图4所示的推演构型,在图3右侧里,正是在文本序列150左右从右侧汇入主线的那个分叉,它也是整个热点网络图中第一个比较明显的推演构型。
3.高潮
小说的高潮通常是矛盾的集中爆发点,各条线索的交汇之地。从文中提取到的关键词,在高潮处往往会集中出现,在关联词频时序图中呈现出某种团簇状的特征。在图2左侧中,2200节到2500节,词汇“飞船”与“战舰”之间,就形成了一个密集的团簇,意味着故事进入了一个高潮。在图3的左图中我们看不到类似的特征,表明在叙事的过程中并不存在明显的爆点。事实上,该小说主体部分的内容是侦探对列车上各式人物的审问过程,以及根据讯问线索进行的思考,节奏确实较为平缓。
为了更清楚地看到这一特征,对于某个特定的关联词频时序图(CWS),我们定义一个含时间的词频集聚函数:
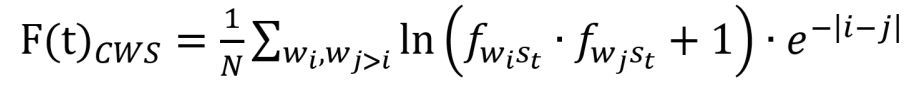
其中的t即为文本序列,它可以看作是一个时间参数。N为该图中关键词的总数,将其引入函数可以消除在不同文本中关键词选取数不同对求和造成的影响,增强函数值在跨文本比较中的合理性。该函数可以反映出不同序列里高频关键词在CWS图中分布的集聚程度,即词频越高的词汇在图中距离越靠近,函数值越大。对词频取自然对数的目的是降低孤立存在的高频词汇对函数的影响。通过F(t)的图像,我们可以更为清晰地看到高潮出现的特征及其所处位置。
如图5(b)所示,在《三体2》中,随着文本进度的推移,集聚函数出现了两处明显的峰值,其一位于全文56%左右,其二位于全文85%左右。通过文本细读,我们可以得知,其对应的情节分别为恒星级氢弹实验、水滴与人类舰队的决战,从整体来看,确实是小说中的两个爆点,这也验证了我们所用方法的有效性。图5(a)的曲线较图5(b)更为平缓,并没有像后者那样数值超过0.1的尖峰,其最大值出现在文本进度98%附近,该处对应于小说中侦探向众人所作的集中推理,也就是最后的解谜段落。事实上在图(b)中的97%进度处,也有一个类似的峰值,它对应于罗辑对其“面壁计划”的解释,同样属于解谜的段落。
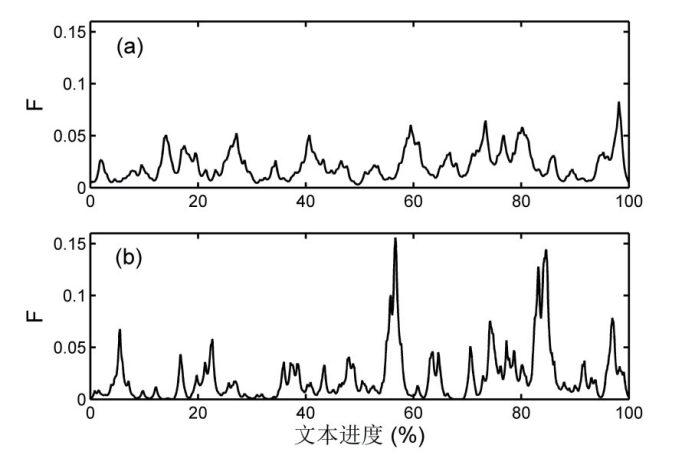
图(a)的源文本为《东方快车谋杀案》,图(b)为《三体2》。
4.解谜
解谜,即在文本最后揭晓所有悬念谜底的阶段。在这个阶段,关键词在CWS图中的分布由发散状态逐渐收束。这种收束特征在热点网络图中呈现得尤为明显。在图2和图3的右图中可以明显看到,随着文本序列的推进,所有的连线都收拢到最后的两三个关键词上。这也使得集聚函数在文末阶段形成一个尖峰,如图5所示。为了确认这种特征是否在解谜型叙事作品中广泛存在,也为了验证和比较解密型叙事在不同类型小说中应用的普遍性,我们需要进行一个基于语料库的跨文本、跨文类的比较。
我们根据豆瓣网读书频道上科幻类作品的综合排序,选取了位于榜单前列的20本长篇科幻小说,同样也根据其推理类作品的综合排序,选取了20本长篇推理小说。[13]其具体篇目如表2所示。
表 2 研究选取的科幻小说和推理小说篇目

按照前文所述的流程,我们选取每个小说中加权TF-IDF值最高的50个关键词,按照统一的文本分块粒度,绘制出所有作品的CWS图,并计算出其对应的词频集聚函数。在对同一文本进度下的函数值进行平均之后,我们得到了一个具有更广泛代表性的结果。

如图6所示,在经过不同小说样本的平均之后,集聚函数的图像明显变得更为平缓。样本中的高潮峰基本已经被弥平,说明不同小说中高潮出现的位置具有较大的分布范围。但我们注意到,结尾阶段的解谜峰仍然具有一定的辨识度,特别是在图6(b)所示的推理小说的组别中,其解谜所形成的尖峰大致位于90%—97%的文本进度范围内,峰值超过0.03,明显高于曲线上的其他部分,是整个图像中最具有指标性的特征。从该结果可以反推,解谜型的叙事结构在推理小说中被广泛使用,而在科幻小说中则只是部分存在,因此其解谜峰的特征不如推理小说那么显著。
结 语
从单个词汇的词频时序分布出发,我们通过抽取50个左右的关键词,可以为特定的文学作品构建一个由众多关联词汇的一维词频分布链所整合而成的二维图像。在本文中,我们以科幻小说《三体2》和侦探小说《东方快车谋杀案》为范例,通过对其关联词频时序图的分析,可以直观地观察到叙事主线、逻辑推演、故事高潮、解谜收束等结构性特征。在引入词频集聚函数后,我们注意到高潮与解谜阶段均对应于函数图像上的一系列峰值。在建立了一个包含大量科幻与推理小说的语料库后,我们对大量文本的平均词频集聚函数进行了分析。结果显示,解谜峰在推理小说组别的图像上仍然是一个最为显著的特征。这表明解谜型叙事在推理小说的创作中被广泛使用。
关联词频时序图在不同的文本分块粒度下,会发生微妙的变化。我们在研究中发现,不同的叙事结构特征对粒度变化的响应方式并不相同。因此,可以通过用粒度标度的特征量来更为细致地提取图像中的不同叙事结构,从而进行更为深入的量化研究。这种方式同样也适用于除了科幻与推理小说之外的其他文类。对粒度标度下的特征量提取方法的构建,以及应用该方法对更为广泛的文类进行的叙事研究,是以后可以继续深入的两个很有意义的拓展方向。
附 录
“堆叠算法”与遍历算法在限制条件下的等价性证明
堆叠算法的基本流程是,首先找到所有词汇中关联系数最大的两个词汇wi与wj,即
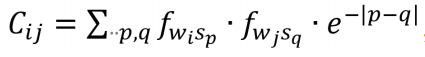
且Cij>∀Cab,把这两个词汇的词频时序条带在相邻位置拼接起来。接下来,再在剩余的词汇中寻找与已拼好部分的边界词汇关联系数最大的词汇,将其拼接在对应的边界词汇外侧。通过这样的方式,不断向两侧扩展,最终得到一个完整的二维图像。
如下图所示,将词汇wi与wj词汇绑定在相邻位置,其余词汇则依据堆叠算法依次排布在其两侧。
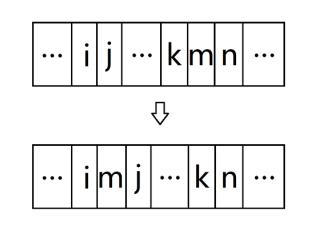
下面将证明,将任一词汇wm插入到词汇wi与词汇wj之间,都将使得整体的关联系数减小。
词汇wm原来的位置在词汇wk与词汇wn之间,比较图中两种排布所对应的关联系数,可知其差值为:

其中
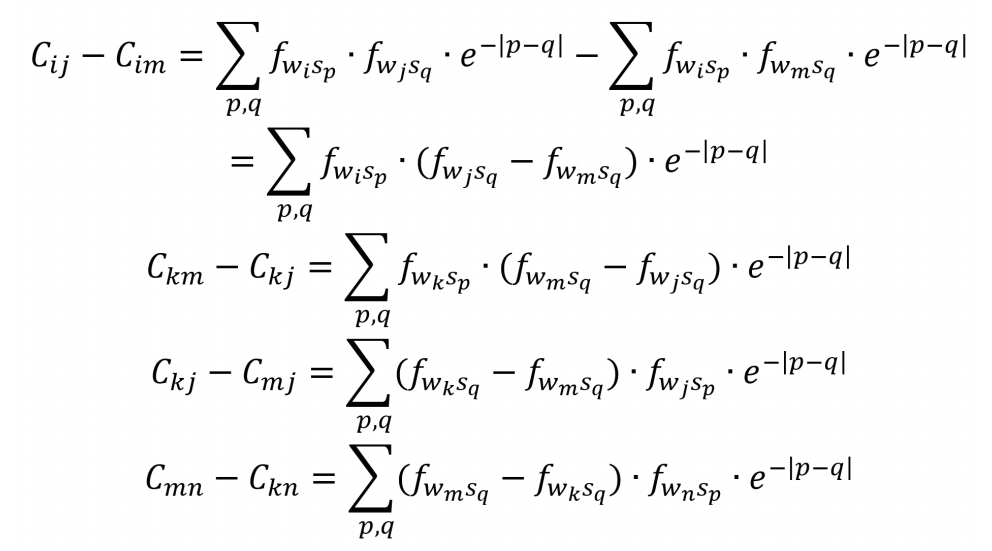
带入上式可得
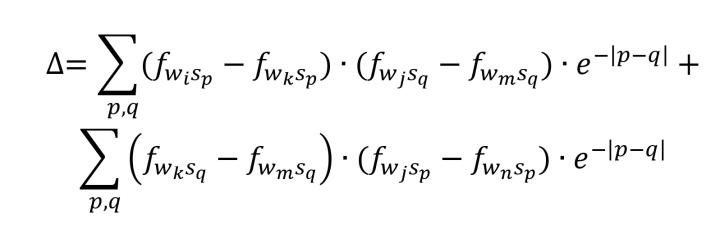
已知Cij>Cim,即

在此引入“共现关联假设”,即认为在计算不同词汇的关联系数时,因为e指数的迅速衰减性,两个词出现在同一序列中(即p=q时)所计算得到的关联值
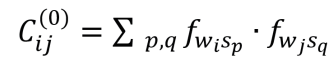
构成了关联系数总体的绝大部分。因此,当Cij>Cab时,

虽然这只是一个不严格的假设,但在篇幅较长、时序切片较多的文本中,这一假设往往都是成立的。在程序中,我们也会对这一假设进行验证,当验证成立时,才进行下一步的排序。在本论文的研究过程中,所有文本都满足此项假设,没有例外。基于此,我们有:
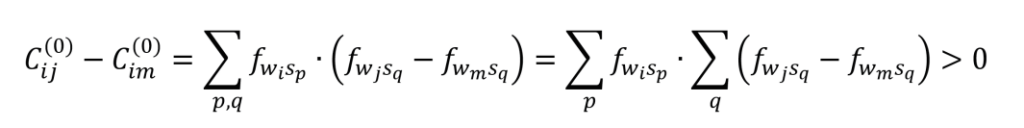

此外,若词汇wk左侧的词汇为wg,根据堆叠算法的顺序流程,应该满足Cgk>Cgm,否则词汇wm就应该排在wg右侧,而不是词汇wk。于是,由

可得:
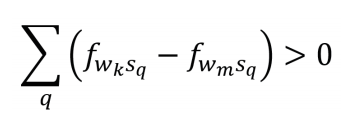
结合之前得到的几个不等式,于是我们有
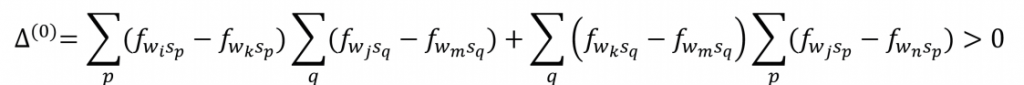
根据“共现关联假设”,∆>0,也就是说,词汇wm的插入,让系统整体的关联系数减小了。
通过相似的方式,可以证明将任意位置的词汇wm,插入其内侧的任意位置,都会使系统整体的关联系数减小。在此不再赘述。
综上所述,在“共现关联假设”成立的前提下,堆叠算法和遍历算法得到的排序是一样的。也就是说,如果我们的关联系数只考虑p=q的共现项,则两种算法是等价的。由于e指数随着时序差值会迅速衰减,在大部分情况下,共现关联占据了总关联数值的绝大部分。因此,我们认为这种堆叠算法可以很好地逼近遍历算法的结果。
———————————————————————————————————————–
The Puzzle-solving Narration in Science Fiction and Detective Novels: A Distant-reading and Visualization Study Based on Word Frequency Dynamics
Liu Yang
Abstract: By integrating the one-dimensional word frequency distribution chain of a single word and optimizing the correlation coefficient, a two-dimensional image reflecting the narrative structure of the text can be obtained. Taking The Three Body Problem 2 and Murder On the Orient Express as examples, by analyzing the correlated word-frequency sequence diagram, we can intuitively observe the structural characteristics of the narrative main line, logical deduction, story climax and puzzle-solving shrinkage. In the image of word frequency clustering function, there are specific peaks in the climax and puzzlesolving sections. After analyzing the averaged word frequency clustering function of a large number of texts, it is found that the puzzle-solving peak is the most significant feature in the image of detective novel group, which indicates that the puzzle-solving narration is widely used in the detective novels. This method based on dynamic analysis of word frequency is an effective distance-reading and visualization scheme for narrative text.
Keywords: Narrative Structure; Word Frequency Dynamics; Puzzle-solving Narration;Distant-reading; Visualization
———————————————————————————————————————–
(编辑:赵薇)
注释:
[1]R. A. Freeman,“The Art of the Detective Story,”Nineteenth-Century and After, London: Dodd, Mead, 1924.
[2]参见陈晓明:《空缺与重复:格非的叙事策略》,《当代作家评论》1992年第5期;申丹:《多维进程互动——评詹姆斯·费伦的后经典修辞性叙事理论》,《国外文学》2002年第2期;张德明:《〈藻海无边〉的身份意识与叙事策略》,《外国文学研究》2006年第3期;王雅丽、管淑红:《小说叙事的评价研究——以海明威的短篇小说〈在异乡〉》为例,《外语与外语教学》2006年第12期;谭敏、赵宁《迷失在逃离与回归之间——析门罗短篇小说〈逃离〉的叙事策略》,《北京第二外国语学院学报》2011年第6期。
[3]A. Don et al, “Discovering Interesting Usage Patterns in Text Collections: Integrating Text Mining with Visualization,”Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management, CIKM 2007, Lisbon, Portugal, November 6-10,2007.
[4]张旋等:《金庸小说中主角复杂爱情模式的识别与分析》,《中文信息学报》2019年第4期。
[5]胡启月、刘彬、高剑波:《哈利波特系列电影的客观评价:基于台词情感自相似分形分析》,《数字人文》2021年第1期。
[6]Q. Hu et al, “Dynamic Evolution of Sentiments in Never Let Me Go: Insights from Multifractal Theory and its Implications for Literary Analysis,”Digital Scholarship in the Humanities, vol. 36, no. 2, 2021, pp. 322- 332; Q. Hu et al, “Fractal Scaling Laws for the Dynamic Evolution of Sentiments in Never Let Me Go and their Implications for Writing, Adaptation and Reading of Novels,”World Wide Web, vol. 24, 2021, pp. 1147- 1164.
[6]K. L. Nielbo et al, “A Curious Case of Entropic Decay: Persistent Complexity in Textual Cultural Heritage,”Digital Scholarship in the Humanities, vol. 34, no. 3, 2019, pp. 542-5421.
[7]Teresa Snelgrove, “A Method for the Analysis of the Structure of Narrative Texts,”Literary & Linguistic Computing, vol. 3, 1990, pp. 221-225.
[8]L. Hess, C. Bary, “Narrator Language and Character Language in Thucydides: A Quantitative Study of Narrative Perspective,”Digital Scholarship in the Humanities, vol. 35, no. 3, 2020, p. 557.
[9]施聪莺、徐朝军、杨晓江:《TFIDF算法研究综述》,《计算机应用》2009年第s1期。
[10]宁建飞、刘降珍:《融合Word2vec与TextRank的关键词抽取研究》,《现代图书情报技术》2016年第6期。
[11]图中箭头所示位置。
[12]这里的“节”指的是根据算法对文本分块的一个单元,并不是原始文本中作者所分的章节。
[13]为了增强作品间的可比性,只对榜单中的长篇作品进行了计算,短篇合集不在计算范围内。
转载请联系授权。