您正在访问旧版存档页面。This is the old version archive of our site.

经典、细读与方法的演变

马修·威尔金斯 / 美国康奈尔大学信息科学学院
陈大龙(译) / 浙江大学国际联合学院
我有一个出发点:经典是存在的,而且我们应该对它们做些什么。数字人文为这个问题提供了一个潜在的解决方案,但前提是我们愿意重新思考我们数字研究中的重点,强调定量方法和它们所依赖的大型语料库。
直到最近我被一个年长的同事责备了,我才意识到自己关于经典存在和有必要对经典开展研究这个主张是危险的。他说我这个主张已经过时30年了。他的意见是,很早之前就已经有过这样的争论,而且经典已经输了。但我很抱歉地说,我是对的,而他是错的。可以去问问那些为学位综合考试而阅读的研究生或者英语教授,谁会承认自己没有读过哈姆雷特。正如我所说的,经典是存在的。我所说的经典,也许不是阿诺德—布鲁姆[1]意义上的经典,那是一份列举伟大书籍的单一的清单;在任何情况下,也肯定不是曾经定义该领域的死去的白人男性作家的那份名单。而是,在更多元的意义上,一个人真的需要读过哪些书才能参与到这个学科中来,是我们中的许多人都向自己的学生教授的书,这些都是经典。经典是存在的。
那么,这样有关经典性的问题,在它出现的几十年后,为什么如今又以某种方式出现了?为什么我们仍然有这些经典?如果我们都同意经典是不好的,为什么我们没有废除它们?为什么我们只是在边缘上修修补补,这里增加一个拖妮·莫里森[2],那里减去一个约翰·德莱顿[3]?我们要怎么处理这个问题呢?说得更直接一些,这跟数字人文、跟数字研究内部的辩论有什么关系?
丰富性的问题
“为什么我们还有经典?”这个问题的答案,说起来简单,但解决起来显然很难。尽管每年产生的文本数量都在增加,但我们的阅读速度并不比以前快。如果我们需要阅读书籍以便从中提取信息,如果我们需要阅读共同的东西以便谈论它们,那么我们就会把大部分时间花在相对较小的文本集合上。这个文本集合的构成内容会随着时间而改变,但它的规模永远不会变大。这就是经典。[4]
为了正确看待这个问题,请考虑过去几十年文学创作的规模(如图1所示)。其中有两个情况很突出。首先,每年都有大量的新书出版,且在过去十年里数量增长迅速。即使(像这里的数据一样)不包括电子版和按需印刷的作品,仅美国的长篇小说新作每年就有五万部甚至更多(在国家划分与文化生产相关性越来越低的情况下,世界其他地区也至少有同样多的作品)。全美图书市场的增长速度并未超过整体的经济增长(几十年来,出版收入占GDP的比例一直保持不变,约为0.2%[5]),但它现在被更多的作品所分割。这很可能是出版的各个环节,从采访到发行再到营销,成本都在下降的结果。出版文本数量的激增肯定是件好事,因为它代表了进入市场的作者更多,读者的选择也更多(至少从原始的数据来看是这样)。但这也意味着我们每个人实际上只读到了当代小说中微不足道的一部分(约为0.1%,往往还更少)。我们可以把这种情况称为丰富性的问题。随着时间的推移,这个问题显然越来越严重。
关于图1,还有一个情况我们还应该注意到:尽管2000年以前每年出版的作品数量要少得多,但在绝对意义上,也并不低。几十年来,每年都有成千上万的新小说出版。再往前看,英国出版商早在18世纪末平均每周出版的小说就不止一部了;[6]美国出版商在19世纪中期也达到了同样的水平。[7]因此,尽管我们现在的阅读量还不如十年前,但阅读量无法跟上当代文学创作的事实却并不新鲜。无论我们是否愿意承认,几个世纪以来,丰富性问题可能程度不同,但一直都存在。

图1 1940年至2010年间美国每年新出版小说的数量
资料来源:1940—1991年数据来自Greco等人;[8]1993—2010年数据来自R.R.Bowker。[9]考虑到Bowker公司后来在方法上的变化,对1991年及以前的图书产出进行了调整(向上调整了3倍)。
这个问题的另一种说法就是,我们要决定略掉什么不读。而我们几代人都满意的答案是,“几乎所有写过的东西”。即使我们勤奋地阅读,也读不了很多。但我们所读的很少,远不能代表整个文学和文化生产领域的情况,正如几十年来对我们现有经典的批评者正确地观察到的那样。在当代的情况下,我们读的主要是那些由主要出版社积极推广的少数书籍,而且几乎都是经过商业出版审查的书籍。当我们试图在形式和内容上做得更好、更具包容性或代表性时,我们实际上有一套根深蒂固的文化偏见,而这些偏见在很大程度上是我们看不到的,而且(因为我们读得太少)对它们的替代品一无所知。这就是说,我们并不明确该如何修正我们的经典,因为我们根本就不知道它们目前偏在哪里。坦率地说,我们做得比五十年或一百年前那些死去的白人男性好不了多少,而且在智力范围的错觉上我们同样地自以为是。更重要的是,随着未读书籍的存量逐周增加,问题日益严重。
因此,即使在其目前的、温和的多元文化主义形式中,经典也是一个巨大的问题。这个问题缘自我们文学学者单一的工作方法,即总是并且单独地把细读作为一种文化分析手段。至少一些从事数字文学研究的学者,可能很清楚我的意思。我们需要少做细读,多做其他任何可能帮助我们从文本提取信息、提取有关文本信息的工作,这些文本会体现大的文化问题。这些工作包括图书计量学(bibliometrics)、图书史研究、数据挖掘和定量文本分析、图书贸易和其他文化产业的经济研究、地理空间分析等。弗朗科·莫莱蒂(Franco Morreti)的研究就是一个明显的模式,迈克尔·维特莫(Michael Witmore)对现代早期戏剧的研究[10]和尼古拉斯·达梅斯(Nicholas Dames)[11]对19世纪小说社会结构的研究也是如此。
实例:文本提取和制图
我们绘制了1851年出版的37部美国文学作品中提及的地点的分布地图。这些文学作品中有一些完全经典性的作品,包括赫尔曼·梅尔维尔的《白鲸》(Moby Dick)和纳撒尼尔·霍桑的《七角楼》(House of the Seven Gables),但大部分是T.S.阿瑟(T.S. Arthur)和西尔瓦努斯·科布(Sylvanus Cobb)之类作者的不知名小说。当然其中很多我没有读过,也不可能花几个月的时间去读。这些文本来自“赖特美国小说集”(Wright American Fiction Collection)[12]项目,约占当年出版的美国文学作品总数的三分之一。[13]赖特小说集基于莱尔·赖特(Lyle Wright)的《美国小说,1851—1875》[14],该书试图确定和列出这一时期美国作家在美国出版的所有长篇形式的小说。地名提取使用的工具是Geodict,它能寻找与大型数据库中的地名相匹配的文本字符串。[15]对提取的部分进行一些清理是必要的,主要是因为许多人名和普通形容词也是世界上某个地方的城市名。我的做法比较保守,把所发现的此类地名都剔除了,并要求在城市和地区名称前使用介词。所以,可能存在的问题就是,一些有效的地方也被排除了。但是,所发现的是很有意思的。
这张地图中的数字,有两点特别值得注意。首先,国外的地点出现得比人们想象的要多。诚然,这些地点许多是在英国和西欧,但结果依然令人吃惊,因为这是美国小说,而不是英国或其他国家的翻版。而且这些小说还多次提到了南美洲、非洲、印度、中国、俄罗斯、澳大利亚、中东等地的地名。19世纪中期美国小说的想象力呈现为相当多样化的外向型,而这一点尚未得到很多关注。实际上,在我们对这一时期小说理解的标准模式中,它们的典型特征之一就是,在个人和国家层面都具有强烈的内省性,主要关注美国的身份和归属感。
其次,在美国南方出现了一个明显的地点群。在某种程度上,这也许不应该令人惊讶,因为我们谈论的书就出现于南北战争十年前,南方肯定是人们关注的地方。但这与我们目前关于浪漫主义和美国文艺复兴(American Renaissance)的叙事并不相称,这些叙事在1850年代初牢牢围绕着新英格兰,并主导着我们对这一时期的理解。也许我们至少需要考虑这样一种可能性,即美国的地域特征分化比我们通常所宣称的要早得多。
将这些结果与赖特小说集语料库的其他年份相比,结果如何?请看下页图2和图3,这两幅分别是1852年和1874年的局部地图,比1851年稍显嘈杂,因为对这些数据的审编较少,但地点分布的模式与之前所见大致相似。[16]然而,在比较南北战争前后出现的地点时,有两个特点非常突出:
1.1874年小说中提及的美国西部地点的密度明显高于1852年。
2.在美国中南部出现了第二个明显的地点群,这个地点群在1852年的地图中依稀可辨,而在1874年的地图中则更为明显。
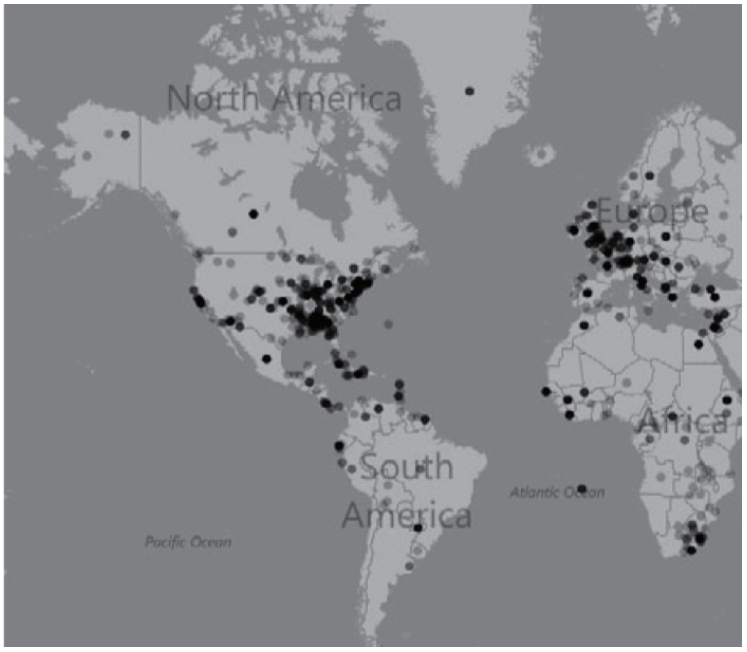
图2 1852年出版的45部美国小说中提到的地点(局部)

图3 1874年出版的38部美国小说中提到的地点(局部)
这两个变化都为我们修正对美国地域性特征的理解提供了潜在的证据,特别是西部和中南部地区进入美国小说想象力范围的时间大大早于这两个地区有意义的出版活动的出现时间。我们想要知道更多关于西进扩张的社会历史和这些地点在这一时期的文学作品中的具体使用方式,然后才能就它们之间的相关性得出有力的结论。但很明显,这类信息能够成为有关19世纪美国小说发展进程的任何新叙事的重要组成部分。
不过,值得一提的是,三张地图在整体上具有惊人的相似性。南北战争是美国文学史上的一个划时代的事件。这里所讨论的书籍(1851—1853年和1873—1875年两个时期各一百多本)大约相隔一代人,分别在战争前十年和后十年写成。如果说文学对快速的社会转型做出了回应,那么我们就应该能在赖特小说集中观察到文学的显著变化。因此,问题就是,我们是否在数据中看到了,南北战争前后文学创作的相应方面发生了有意义的转变?答案是,这取决于我们对“有意义”的理解。我们对文学和文化生产发生重要转变的理解,是来自于我们对少数据称有意义或有代表性的作品的经验。由于我们只能研究极少数的文本并对它们的特殊差异进行高度详细的描述,这也许就使得我们把时代差异(和其他分类区别)看得比它们的实际情况更大。这并不是说不同时期、不同流派、不同国家、不同性别等之间的差异不存在,而只是说这些差异可能是存在于更广泛的基本连续性上的微小却重要的变化之中。
基于整体文学创作中的微小变化而对文学进行分类的方案,当然没有否定像周期化这样的概念,但是,对我们利用大型语料库这种长期以来处于方法论范畴之外的研究方法,它确实具有严肃的涵义。当问题开始涉及成百上千本书之间的模式和差异时,遇到更多类似上面地图中这样的数据实例几乎是肯定的。在这些实例中,我们会观察到在不同语料库中都广泛存在着微小特征变化。对此,根据我们建立的基于事件变化的模型,能做出的一个可能的解释将是:并没有发生显著的根本性变化。也许我们甚至会说,文学史最好被理解为,(最多是)渐进的演化步骤构成的一个基本上不间断的链条。也许就是这样。但我们还应该意识到,对于大型文学体的形式或内容的重大变化可能是什么样子,我们目前几乎没有概念。在其他背景下,以一个特定度量方式得到的小的绝对变化具有文化上(或物理上)的意义,这当然是可能的。例如,一次势均力敌的全国性选举和一次一边倒的投票两者之间的区别。如果我们对只有10%或20%的变化做出的反应是,它们远远没有达到我们的“转型”概念的标准,那么需要改变的可能正是我们对什么是“转型”的理解。
还有一个方法上的说明:只要获得了新的文本,这里涉及的技术就可以很容易地扩展运用于其中,并不需要付出多少额外的时间或劳动。这一点很重要,因为这使得我们能够用新的材料、不同的配置和时代来检验我们的假设,这靠手工是很难甚至不可能做到的。当然,我们无法保证能够解释我们所发现的东西,也无法保证它与我们迄今所见完全吻合,但这是一个特点,不是缺点。有更多的材料可供评估和分析是件好事。这些方法的相对速度也是一个优势,因为它使我们能够寻找潜在的有趣的特征,而不需要投入数月或数年的时间通过细读来提取它们。我们很可能仍然需要细读一些文本,但文本挖掘方法使我们能将有限的注意力投入到那些我们已有理由相信能从中找到相关信息的材料。虽然我们还不习惯用快速假设检验和特征提取的方式来构建我们的研究,但这个过程与我们已经做过的较小规模的研究并非完全不同。速度快和可扩展性(scalability)强是这种计算研究的主要优势。
结果和结论
我认为,前面介绍的地图提供了有趣的初步结果。这些结果展示了一种文学和文化分析的最初几步,而这种分析不再单单依赖于细读,也不受这种阅读所带来的材料限制。我认为,我们应该多做这种研究——并非一定要在19世纪中期的美国小说中提取更多的地理位置(尽管我所展示的显然没有穷尽这项研究),但对规模大得无法“直接”处理的文本,肯定要进行更多的算法和定量分析。“直(接”被打上了吓人的引号,因为在这种情况下,它是细读的一个有严重误导性的同义词。)
如果我们这样做,把更多的思辨能力转移到这样的项目上,就会出现几个重要的结果。首先,我们极可能会成为更坏的细读读者。时间有限,我们投入某项活动的时间越少,在该领域的技能发展就越差。我们的阅读究竟会受到多大的影响,我们应该多在乎它,这些都是可理性争论的事项。这些问题取决于两个方面:转变的程度大小和细读的技能—经验曲线的形态。我的感觉是,结果会很好。用更多的数字换取更少的文字,这是一项值得进行的交易。通过(比如)文本挖掘所提供的各种证据,我们会获得很多东西,其结果几乎肯定会对该领域产生积极影响。我愿意承认,这一点要在实践中才能证明,而实践还相当有限,尽管很有希望。但重要的是,将文学和文化分析等同于目前研究它们的方法,这样做是错误的,只有这种情况下细读的衰落才是消极的、否定性的。
对于我们这些已经在从事某种数字项目的人来说,第二点是辩论的核心:我们需要看到数字人文自身范围之内的相关资源的重新分配问题。在过去的几十年里,数字人文最引人注目的项目许多都是围绕着经典文本、作者和文化艺术品组织的。这些项目的动机是希望在一个明显来自传统人文学科的模式下更有力、更完整地理解这些(相当有限的)对象。这并不是错误,这些项目也不是没有重要价值。比如,它们为我们理解克里斯提娜·罗塞蒂和瓦尔特·惠特曼、斯托夫人和艾米丽·迪金森、威廉·莎士比亚和埃德蒙·斯宾赛等做出了贡献。它们通过展示新技术能在多大程度上扩展传统的学术研究,使数字研究在学界同仁的质疑中合法化。它们为世界各地的学者,包括那些在大学权力中心之外的学者,提供了更好的途径来获取稀缺的资源,并通过同样的方式提供改进了的教学法。但我们不应忽视这样一个事实,即建立如此庞大而昂贵的研究的前提假设,往往是我们已经知道了应该把这些稀缺资源投入到哪些作者和文本上。而通过它们吸引到批评关注,这些项目的成功也强化了其主题的经典性。
那种破坏而不是强化经典的计算和量化研究需要更多的材料,而不是精心的开发。前述地图所依据的赖特小说集,就是最适合数字人文研究下一步发展的资源的例子。它包括(或将包括)1851年至1875年期间在美国出版的所有已知的美国文学作品,并以可机读的形式提供基本元数据。谷歌图书和Hathi Trust的目标是在更大的范围内做同样的事情,目前已经覆盖了现存公共领域的很大一部分,并有希望实现通过计算机访问主要研究型图书馆所持有的大部分书籍(不管是否在版权保护期内)。这些项目都不便宜。但按册计算,它们又是非常实惠的,主要是因为它们在准备文本的过程中,(通过例如详细的标记等方法)避免了大量人工的参与。当然,谷歌和Hathi语料库的制作,对使用它们的学术部门来说,直接成本非常有限,特别是考虑到它们的规模。与那些特定作者、特定主题的档案研究项目中经过审编的文本相比,这些项目所包含的文本是非常贫瘠的。但对于我们的许多分析目的来说,它们已经足够了,而且我们的分析也不单需要精细的文本阐释学。
使用这些我们可以称之为“裸”(bare)存储库的东西,仍然所费甚多。所需要的时间、金钱和注意力必得有个来源。但我的观点是,如果(似乎很有可能)我们不能从学科之外的全新资源池中获取这些资源,也即如果不能扩大学科来做我们已开展的所有这些工作,再加上还有大量的新工作要做,那么我们应该会愿意不仅在传统人文学科或类人文学科方面做出牺牲,也会愿意在为数字人文赢得声誉的第一波数字研究项目上做出牺牲。这将会造成伤害,但也会带来更好的、更广泛的、更包容的、最终更有用的人文研究。它将第一次真正给予我们机会来打破小规模的、任意组合的经典对我们思考大规模文化生产的控制。这是一个不容错过的机会,也是一个将我们的钱(实际的和比喻意义上的)放在已经有两代学者在耕耘的领域。对于经典我们已经抱怨很长时间了。现在,我们可能不需要它们了,我们愿意尝试吗?我们愿意接受其中的权衡取舍吗?我认为我们应该这样做。
(编辑:姜文涛)
原文信息:Matthew Wilkens,“Canons, Close Reading, and the Evolution of Method,” ed. Matthew K. Gold, Debates in Digital Humanities, Minneapolis: University of Minnesota Press, 2012, pp. 249-258。翻译及出版已获得作者允许。
注释:
[1]指19世纪的英国批评家麦修·阿诺德和20世纪的美国知识分子阿兰·布鲁姆。——译者注
[2]Toni Morrison,美国当代作家。——译者注
[3]John Dryden,17世纪英国文人。——译者注
[4]究竟有多少经典?答案取决于有多少人需要读过一组特定的材料,才能进行某一领域的研究。这曾经或多或少是指这个领域里每个人都读过的作品,而那时这个领域是非常小的。我的最佳猜测是,这个数字最低至少有一百个或多一点,而最高则比这个数字多出两个数量级,这将使我们在英语领域或多或少有几十个子领域,无论承认与否。我认为这大致上是准确的。
[5]Greco Albert, Clara Rodrguez, Robert Wharton, The Culture and Commerce of Publishing in the 21st Century, Stanford, Calif.: Stanford University Press, 2007.
[6]Franco Moretti, Graphs, Maps, Trees: Abstract Models for a Literary History, New York: Verso, 2005, p. 7.文中引用了多个研究成果。
[7]Lyle H. Wright, American Fiction, 1851-1875: A Contribution Toward a Bibliography, Rev. ed. San Marino,Calif.: Huntington Library Press, 1965.
[8]Albert Greco, Clara Rodrguez, Robert Wharton, The Culture and Commerce of Publishing, 2007.
[9]R. R. Bowker,“New Book Titles & Editions, 2002-2009,” April 14, 2010, http://www.bowker.com/index.php/book-industry-statistics; R. R. Bowker,“U.S. Book Production, 1993-2004,” April 14, 2010, http://www.bowker.com/ bookwire/decadebookproduction.html.
[10]Jonathan Hope, Michael Witmore,“The Hundredth Psalm to the Tune of ‘Green Sleeves’: Digital Approaches to Shakespeare’s Language of Genre,” Shakespeare Quarterly, vol. 61, no. 3, 2010, pp. 357-390.
[11]David K. Elson, Nicholas Dames, Kathleen R. McKeown,“ Extracting Social Networks From Literary Fiction,” in Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 2010, pp.138-147.
[12]Wright American Fiction Project, http://www.letrs.indiana.edu/web/w/wright2.
[13]为什么只有三分之一?因为这些文本元数据质量较高,是目前所有的可机读文本(MONK项目,http://monkproject.org)。
[14]Lyle Wright, American Fiction, 1851-1875: A Contribution Toward a Bibliography, Rev. ed. San Marino, Calif.:Huntington Library Press, 1965.
[15]Peter Warden, Geodict, http://datasciencetoolkit.org.
[16]1853年、1873年和1875年也有数据,每一年显示出的特征都基本相似。介于其间的1854年至1872年,由于数字化图书太少,数据不可靠。另外,非洲南部的地点群已知是一个识别错误。